背景
线上 Linux 服务器 CPU 飙升,告警群一直在告警,告警邮件也收到一堆...
发现就是我们的应用程序进程搞得鬼...
领导就要发飙啦...
PS:以下的示例非线上环境数据,只做演示参考。jdk版本1.8。
如何定位问题
1.我们首先需要定位是哪个进程搞得鬼!
top命令来帮忙,top命令执行后我们可以按P来让这个动态列表按照CPU资源占用率进行排序,那第一个自然就是我们自己的进程了 - -! ps:P重复按就是升序和降序的区分。按M是按照内存使用率排序。
top - 18:48:55 up 6 days, 4:45, 4 users, load average: 2.54, 2.84, 3.23
Tasks: 1272 total, 1 running, 1270 sleeping, 1 stopped, 0 zombie
%Cpu(s): 21.8 us, 1.4 sy, 0.0 ni, 76.5 id, 0.3 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 16267972 total, 177928 free, 14780752 used, 1309292 buff/cache
KiB Swap: 31027336 total, 14823504 free, 16203832 used. 780216 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
13029 root 20 0 6821900 623320 3860 S 79.5 3.8 789:29.60 java
2274 root 20 0 3465764 59296 6148 S 1.3 0.4 52:14.27 dockerd-current
5508 saas 20 0 147272 3300 1444 R 1.3 0.0 0:02.83 top
5794 root 20 0 5246444 571572 6100 S 1.3 3.5 7:05.89 java
2.找到进程之后,我们得知道到底是什么造成了 CPU 飙升啊。一个 Application 那么多线程在执行,我怎么定位是哪个线程呢?
这个时候还是可以通过top命令来解决,我们用"top -p [pid] -H"的方式进行查询。哎~ 发现和步骤1的界面是一样的!OK,这样我们就知道如何进行排序啦~
top - 18:19:16 up 49 days, 33 min, 4 users, load average: 5.32, 4.47, 2.81
Threads: 436 total, 5 running, 431 sleeping, 0 stopped, 0 zombie
%Cpu(s): 74.6 us, 1.5 sy, 0.0 ni, 23.9 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 8008872 total, 151708 free, 5989516 used, 1867648 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 1734508 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1913 saas 20 0 8562676 4.7g 7952 R 68.8 61.8 20:42.29 java
1914 saas 20 0 8562676 4.7g 7952 R 68.8 61.8 20:41.78 java
1915 saas 20 0 8562676 4.7g 7952 R 62.5 61.8 20:41.79 java
1916 saas 20 0 8562676 4.7g 7952 R 62.5 61.8 20:42.87 java
1925 saas 20 0 8562676 4.7g 7952 S 31.2 61.8 2:52.93 java
1895 saas 20 0 8562676 4.7g 7952 S 0.0 61.8 0:00.00 java
1901 saas 20 0 8562676 4.7g 7952 S 0.0 61.8 0:20.29 java
1926 saas 20 0 8562676 4.7g 7952 S 0.0 61.8 0:01.28 java
1927 saas 20 0 8562676 4.7g 7952 S 0.0 61.8 0:01.26 java
1928 saas 20 0 8562676 4.7g 7952 S 0.0 61.8 0:00.00 java
1929 saas 20 0 8562676 4.7g 7952 S 0.0 61.8 3:02.94 java
1930 saas 20 0 8562676 4.7g 7952 S 0.0 61.8 2:58.78 java
1931 saas 20 0 8562676 4.7g 7952 S 0.0 61.8 0:39.37 java
3.我们已经知道那些进程和线程比较耗费资源了,那我们如何查看呢?
jstack工具闪亮登场,如何用?用 jstack -help去查一下吧,不要太懒。 我们可以用 "jstack -l -F [pid]" 查询当前的java进程的线程状态、线程栈、是否有死锁等信息。
截取一段信息如下:
2019-07-29 18:19:21
Full thread dump Java HotSpot(TM) 64-Bit Server VM (25.211-b12 mixed mode):
"Attach Listener" #6576 daemon prio=9 os_prio=0 tid=0x00007fd958053800 nid=0x2445 waiting on condition [0x0000000000000000]
java.lang.Thread.State: RUNNABLE
Locked ownable synchronizers:
- None
"DubboClientHandler-10.111.6.167:20885-thread-593" #6575 daemon prio=5 os_prio=0 tid=0x00007fd90404f000 nid=0x2421 waiting on condition [0x00007fd8d1d80000]
java.lang.Thread.State: TIMED_WAITING (parking)
at sun.misc.Unsafe.park(Native Method)
- parking to wait for <0x00000006f31f6d88> (a java.util.concurrent.SynchronousQueue$TransferStack)
at java.util.concurrent.locks.LockSupport.parkNanos(LockSupport.java:215)
at java.util.concurrent.SynchronousQueue$TransferStack.awaitFulfill(SynchronousQueue.java:460)
at java.util.concurrent.SynchronousQueue$TransferStack.transfer(SynchronousQueue.java:362)
at java.util.concurrent.SynchronousQueue.poll(SynchronousQueue.java:941)
at java.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1073)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1134)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Locked ownable synchronizers:
- None
......
4.我们拿到了线程的一些信息,也知道了那些线程比较耗费资源,那么我们如何去对应线程呢?
这个时候需要注意下,top中的pid和jstack dump出来的线程对应关系。 把top中的pid转换成16进制。如上面步骤中的1913经过16进制转换就是jstack dump中java线程的nid(native thread id)
具体步骤如下:
# 1913由10进制转换成16进制
printf %x 1913
779
printf %x 1914
77a
printf %x 1915
77b
printf %x 1916
77c
# 得到的值查询时需要加上0x,表示16进制
# 在jstack dump出来的文件搜索当前id的线程(-C表示输出该行的上下行数)
cat jstack.dump | grep "nid=0x779" -C 10
# 查出来啦 最终定位到某一线程,此处是GC线程(如下) 或者 可能是一个业务线程栈
GC task thread#0 (ParallelGC)" os_prio=0 tid=0x00007fd99001f800 nid=0x779 runnable
GC task thread#1 (ParallelGC)" os_prio=0 tid=0x00007fd990021800 nid=0x77a runnable
GC task thread#2 (ParallelGC)" os_prio=0 tid=0x00007fd990023000 nid=0x77b runnable
GC task thread#3 (ParallelGC)" os_prio=0 tid=0x00007fd990025000 nid=0x77c runnable
分析解决
- 如果如上面的代码是个 GC 线程,那么可以去看一下 GC 的配置。线程信息中已经标明是 ParallelGC,即新生代的 GC 线程。通过查看我们的 GC 设置发现,没有对 GC 收集器设置参数。java8 默认新生代采用 PSGC。附一张 GC 图...
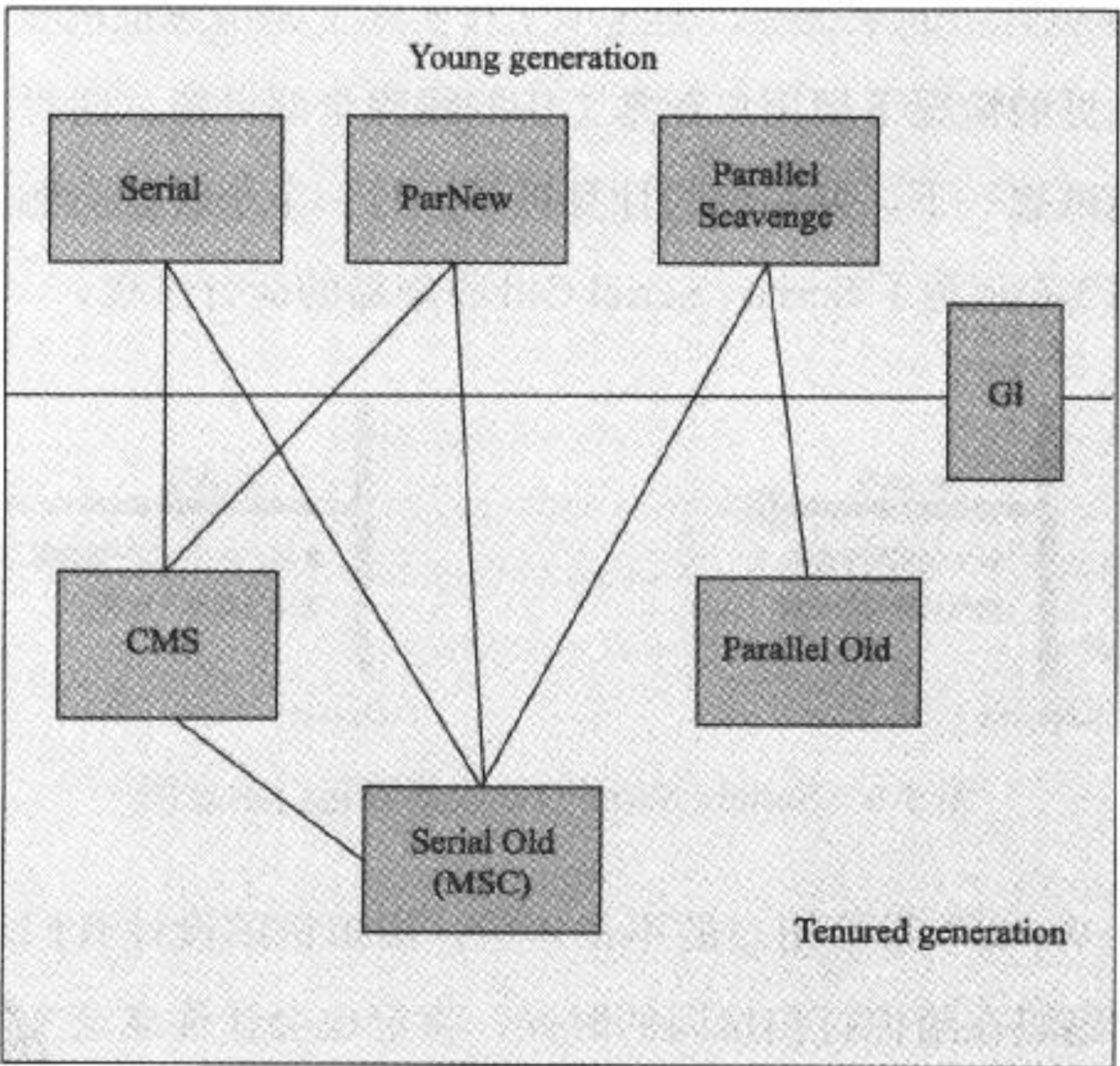
2. 如果是个业务线程,直接看业务线程的栈信息,发现阻塞的那几行代码,直接根据业务场景去解决即可。
3. 当然也有可能碰到一些框架的问题,比如有可能出现 HashMap 的 put 等方法最为耗时,那么这个时候也可以看一下是不是因为 jdk 版本的 HashMap 扩容导致死链循环,或者 put 扩容非常频繁?
总结
- 我们看到前几个步骤的小问题是:手动搞总是比较慢的,等我登上服务器,再执行各个命令,CPU 占用率可能都已经下来了... 所以我们可以通过写一个简单的 shell 来解决这个问题。
- 我们看到后面对线程信息进行分析的时候,一个见名知意的线程名称对我们来说也是非常有帮助的。所以我们在工程中用到线程池的时候,最好是在创建线程的时候设置一个比较合理的线程名称,方便我们排查问题。这个规范可以参考《阿里巴巴 Java 开发手册》
- 学会使用好的工具提升效率 以上步骤我们其实还有更好的工具,比如阿里开源的 arthas 感兴趣的可以看一下文档~
欢迎来到这里!
我们正在构建一个小众社区,大家在这里相互信任,以平等 • 自由 • 奔放的价值观进行分享交流。最终,希望大家能够找到与自己志同道合的伙伴,共同成长。
注册 关于