前言
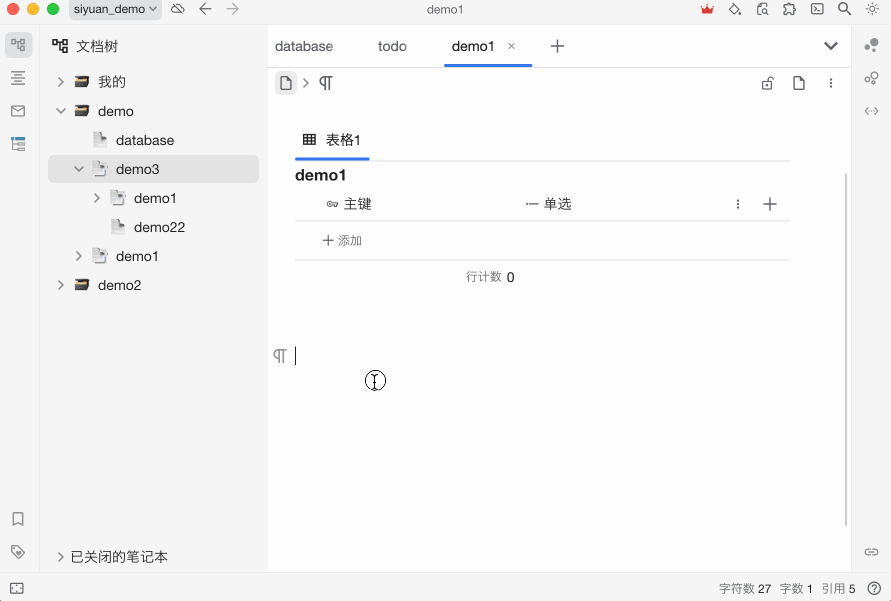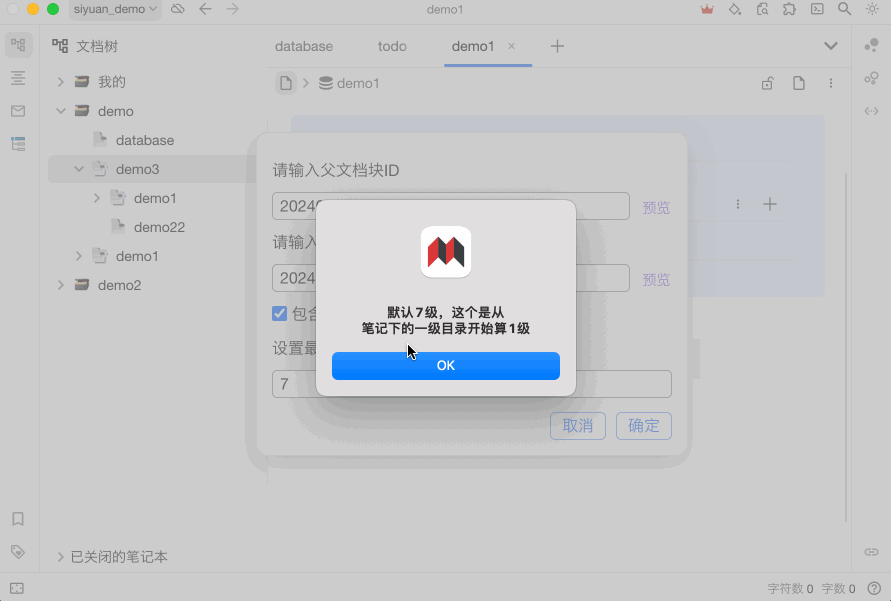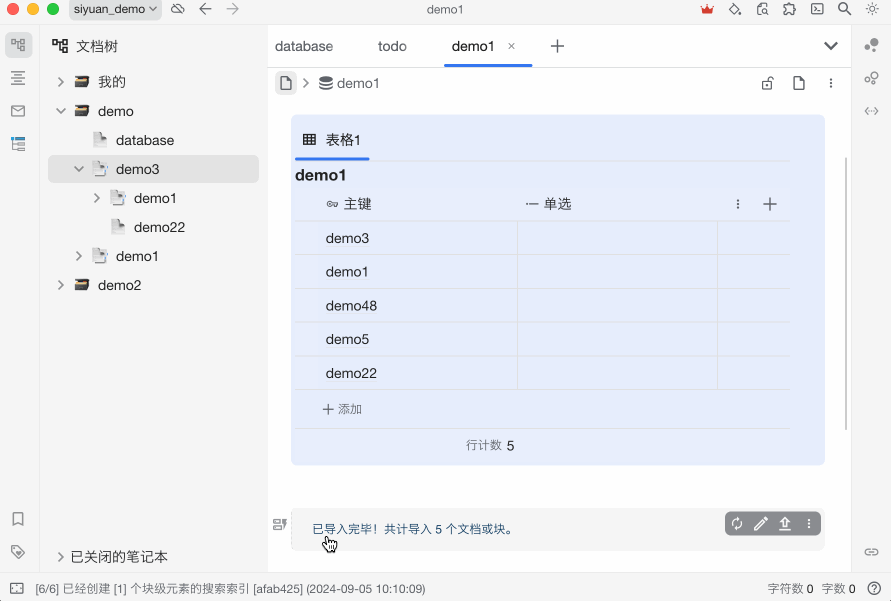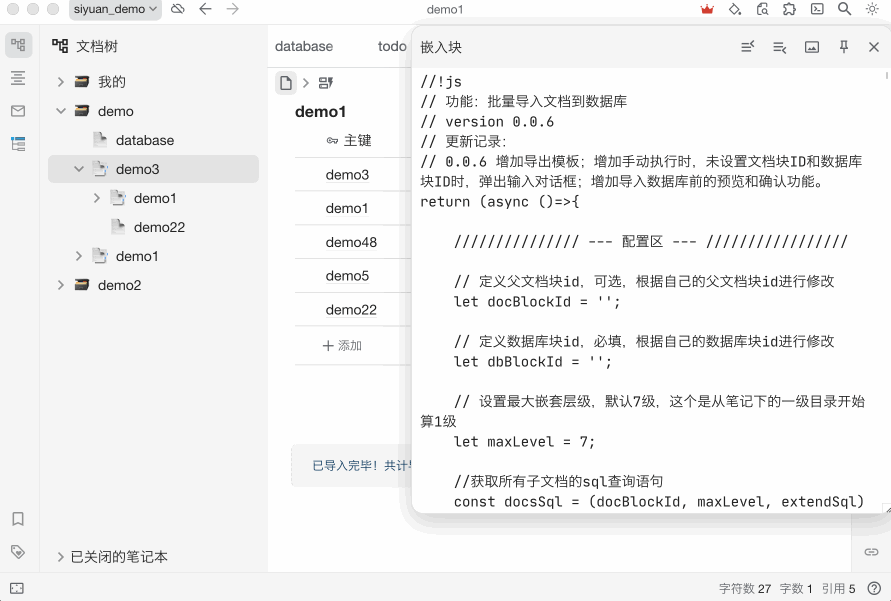
这个脚本的作用就是批量导入文档或块到数据库,包括后代文档等,可以通过限定嵌套层数或通过 SQL 等对导入内容加以限制。
在之前的这个帖子中(该贴不再维护和更新),我实现了 0.0.5 版本,这个版本已经很完善了,只不过使用需通过代码配置,体验上差了些。0.0.6 在这个基础上做了功能扩展,改善了使用体验。
使用效果,先上图
完整代码
使用方法
基本使用
- 下载这个文件批量导入文档到数据库.md.zip,放到/data/templates 目录
- 然后在使用的文档中输入斜杠命令
/》模板 》选择“批量导入文档到数据库”模板即可 - 或者复制上面的代码,然后输入/{{}},在弹出的对话框中输入上面的代码即可
- 事实上就是 SQL 查询脚本,可以在任何文档中使用,按照脚本提示或注释说明使用即可
这个脚本非常灵活,可以调整不同的参数满足不同的需求。
但通常有四大使用场景,这里重点介绍下。
四大使用场景
一、临时使用
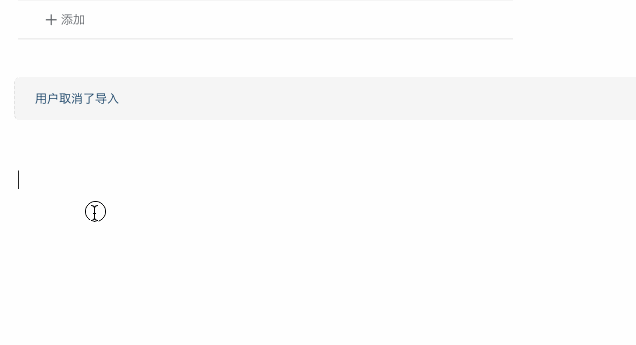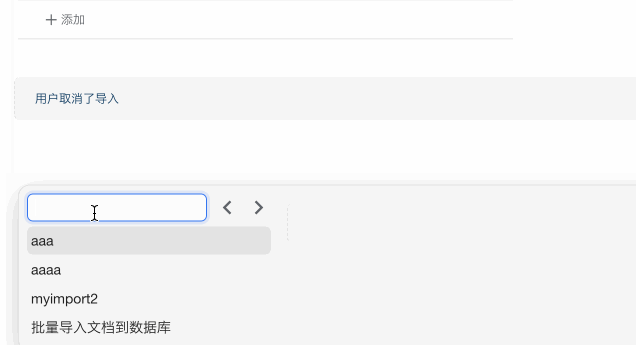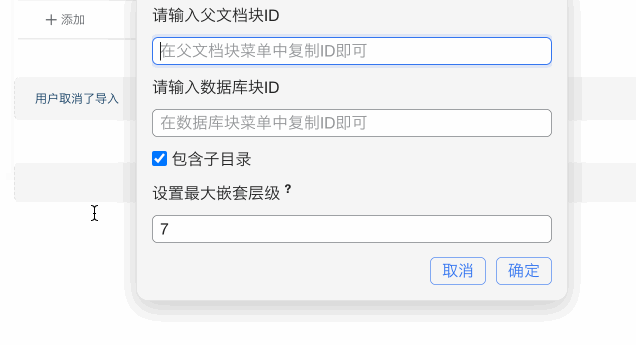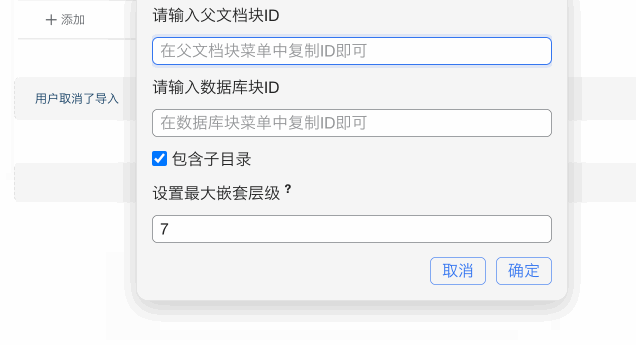
需要要修改参数:
let docBlockId = '';
let dbBlockId = '';
const isShowInputBox = true;
注意,docBlockId 和 dbBlockId 至少一个内容保持为空即可
然后可以保存为模板,然后每次使用时从模板导入即可。
使用演示:
二、自动导入
这个功能,可以满足当打开某个文档或刷新文档时,自动导入某个文档下面的文档到数据库。
需要修改参数:
let docBlockId = 'xxxxxxxxx-xxxx';
let dbBlockId = 'xxxxxxxxx-xxxx';
const runOnLoad = true;
注意,docBlockId 和 dbBlockId 不能为空,runOnLoad 需要设置为 true
使用演示:
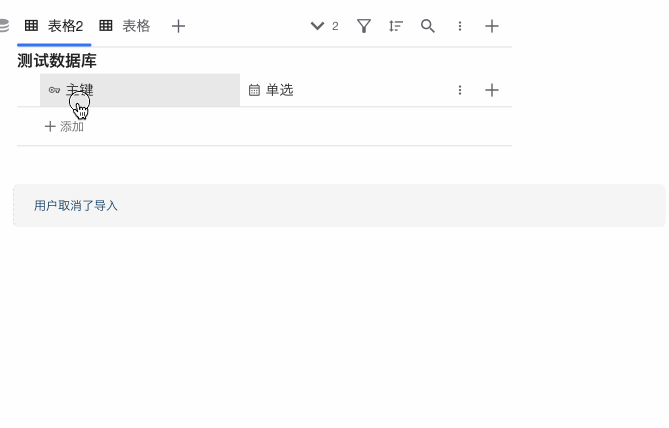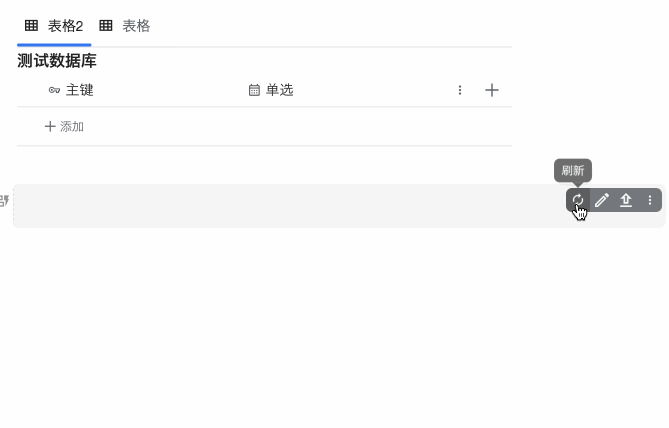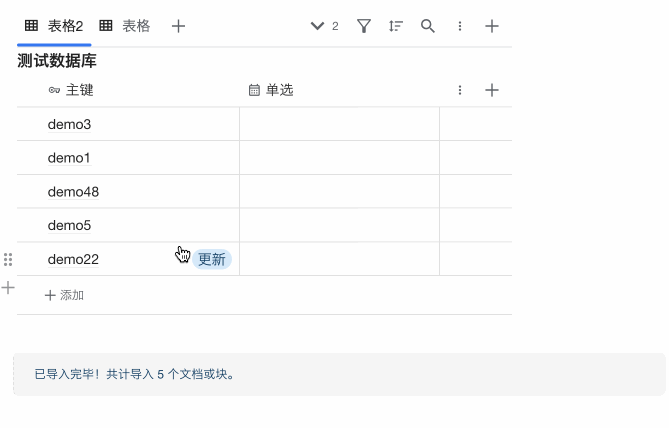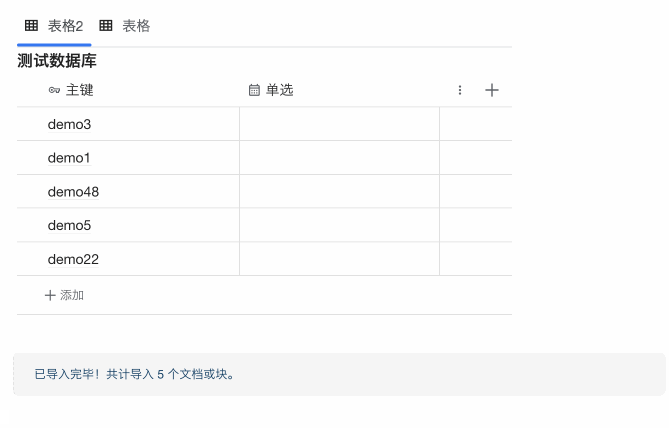
三、手动执行
这个没有特别要求,任何参数配置情况下点击右侧的刷新按钮都可以手动执行。
使用演示:
四,自定义导入
这个就要参考代码中的参数配置和注释并根据自身情况进行设置了,脚本的本质就是根据 SQL 查询语句的内容进行导入的,在这里你可以通过编辑 SQL 进行自定义查询,然后导入。

使用技巧
你可以根据自身的需要对参数或代码进行修改,然后修改完成后,通过到导出到模板按钮保存为不同的模板,以满足不同场景下的需求和复用。

另外,可以在导出模板时修改 shortName 参数和 memo,让不同模板显示不同的名称和备注信息,这样就能很好区分,当前使用的脚本是哪个模板了。
免责声明
文件读写有风险!导入前请做好备份!请在新空间测试无误后再使用!本脚本仅用于学习交流,造成的任何后果均与脚本及作者无关。
打赏作者




