作为一个无聊的科研狗,我不太跟前沿 LLM 发展,更不搞这方面的研究。仅仅是出于个人兴趣和日常使用需求 (再叠加一些 issue 屡次被 CherryStudio 等项目拒绝的愤怒驱动),自己编写了一些与 Chat 相关的代码。
日积月累 sy-f-misc 插件的 GPT 功能在我闲暇时的调教下,如今用起来已颇为顺手(至少对我个人而言)。除了那个一直想做但实现难度颇高的 Tree 结构(非线性)对话模式外,目前主要感兴趣的主要还是 Tool Call 了。
近期 MCP 的概念炒得热火朝天,但在我不负责的眼光看来,本质上还是 Tool Call 的“套皮”。一来我不乐意在自己插件里植入繁琐的第三方依赖包 (我连 OpenAI 对话协议都是自己手搓的);二来市面上看到的 MCP 大多于我而言寡淡无味,跨系统互操作性对我价值不大,反而引入更多依赖和约束。
考虑到插件主要是编写给我自己用,不对他人负责,所以我也没兴趣去跟这个风,不如继续按着自己的性子,走“野路子”折腾 LLM。
顺着这股野感,最近忙里偷闲整出了两个自认为挺好玩的功能 (虽然对大部分人来说没啥卵用)。顺手写篇文章分享一下,如果有玩 LLM 的专业人士看着碍眼,且当一乐关掉网页就是。
两个功能:第一个是基于 Python 脚本的工具扩展;第二个是 ToolCallScript。
这两个功能是 7.3 版本开始有的,由于是实验性功能,并没有在集市正式发布,只有我自己在当小白鼠测试员。
感兴趣的要么等我正式发布,要么自己去 github release 区下载。
1. 基于 Python 脚本的工具扩展
这个功能的诞生,主要是为了解决工具包扩展不方便的问题。痛点有二:
- 流程繁琐:插件的工具通常是内置的。想要增加 Tool 或 ToolGroup,得打开插件源码、写 TypeScript、重新编译、重新安装。太麻烦。
- 环境受限:在思源插件(JS/TS)环境下运行的功能,本身受到诸多限制,懂的都懂。
琢磨了一下,我想要的理想状态应该是:不需要重新编译插件,不需要写冗长的 Tool 类型定义,随插随用的工具扩展体系。
最后拍脑袋一想:靠外部脚本挂载呗。
简单来说,玩法是这样的:
首先,指定一个固定的目录 snippets/fmisc-custom-toolscripts。

起初里面是空的,没关系,我们直接创建一个 Python 脚本,比如 sample.py:

代码就是最普通的 Python,比如这样:
但是注意要做好类型标注,这个很关键。
import os
__doc__ = """doc 属性会被当作模块的规则 prompt 使用"""
def _utils():
# 以 _ 前缀开头的函数,会被视为内部工具类,不会被解析为 Tool
pass
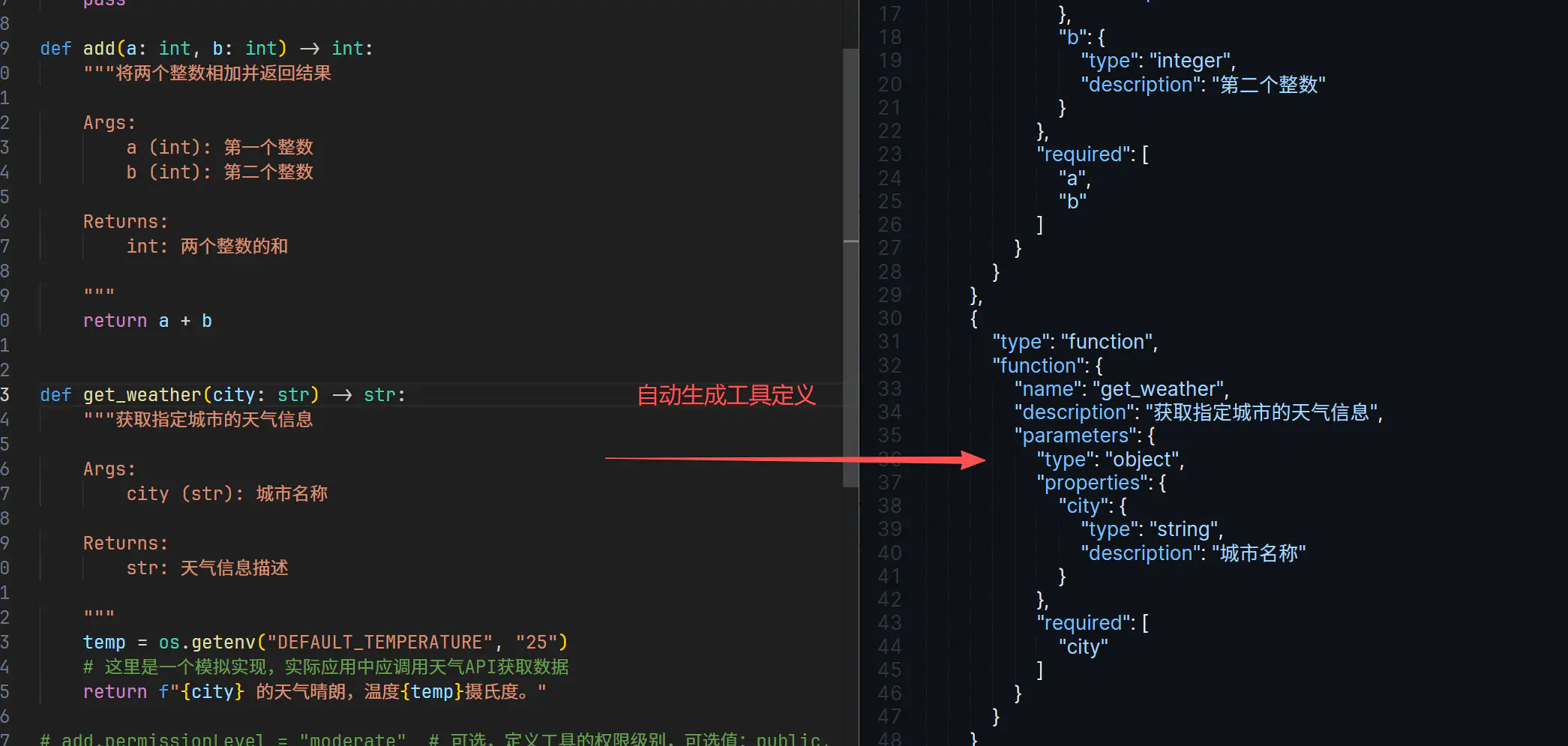
def add(a: int, b: int) -> int:
"""将两个整数相加并返回结果
Args:
a (int): 第一个整数
b (int): 第二个整数
Returns:
int: 两个整数的和
"""
return a + b
def get_weather(city: str) -> str:
"""获取指定城市的天气信息
Args:
city (str): 城市名称
Returns:
str: 天气信息描述
"""
temp = os.getenv("DEFAULT_TEMPERATURE", "25")
# 这里是一个模拟实现,实际应用中应调用天气 API 获取数据
return f"{city} 的天气晴朗,温度{temp}摄氏度。"
看起来平平无奇?接下来才是关键。
打开 fmisc,点击「解析所有脚本」。
注:需要本地安装 python,且安装 doc-string 库
sample.py 文件会自动被解析为一个工具组,里面定义的对外函数(非 _ 开头)也会摇身一变,成为 LLM 可调用的工具。
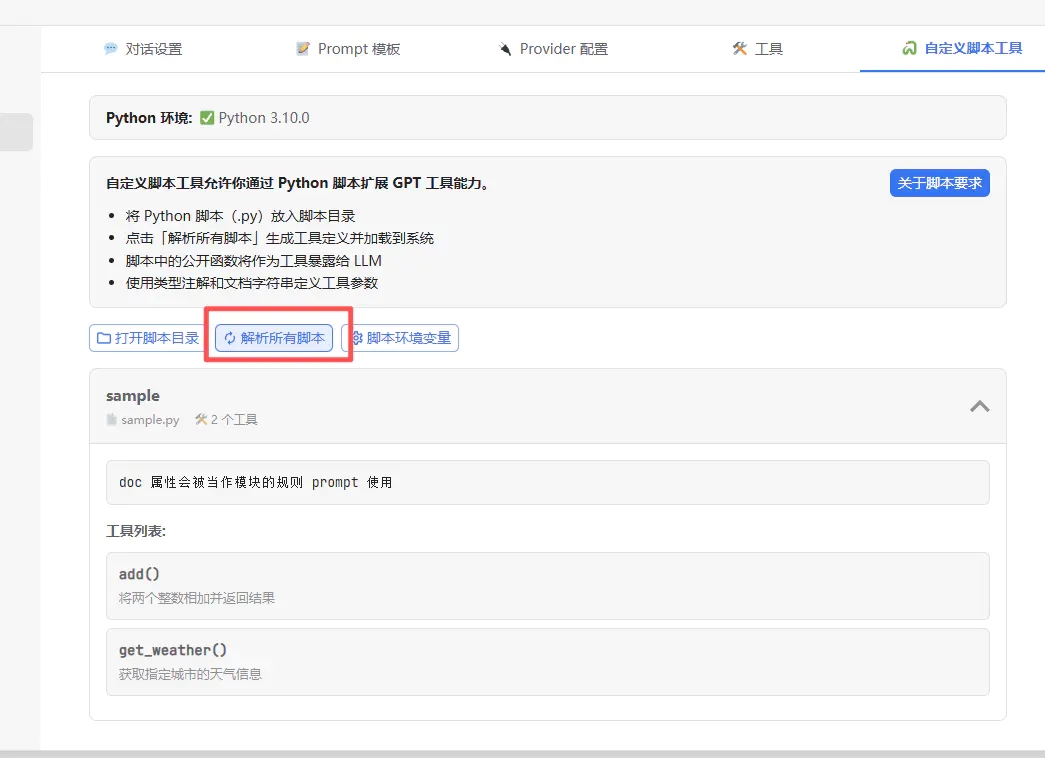
此时回到对话框,就可以直接启用这个工具了:
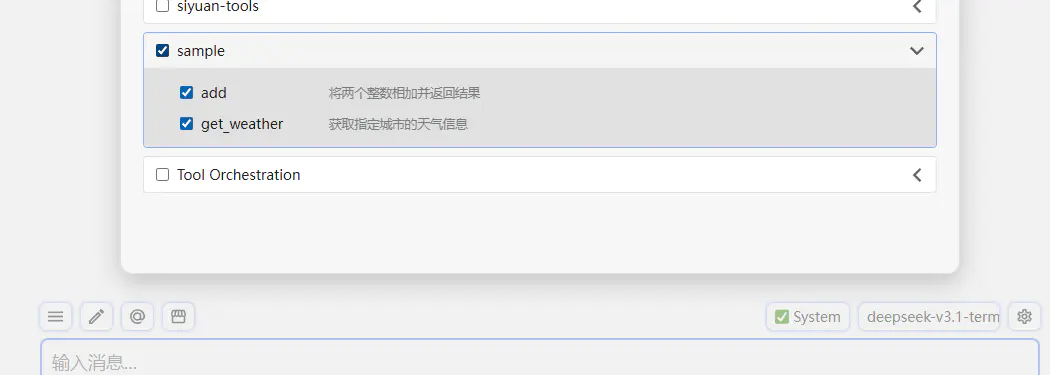
然后就能直接用了:
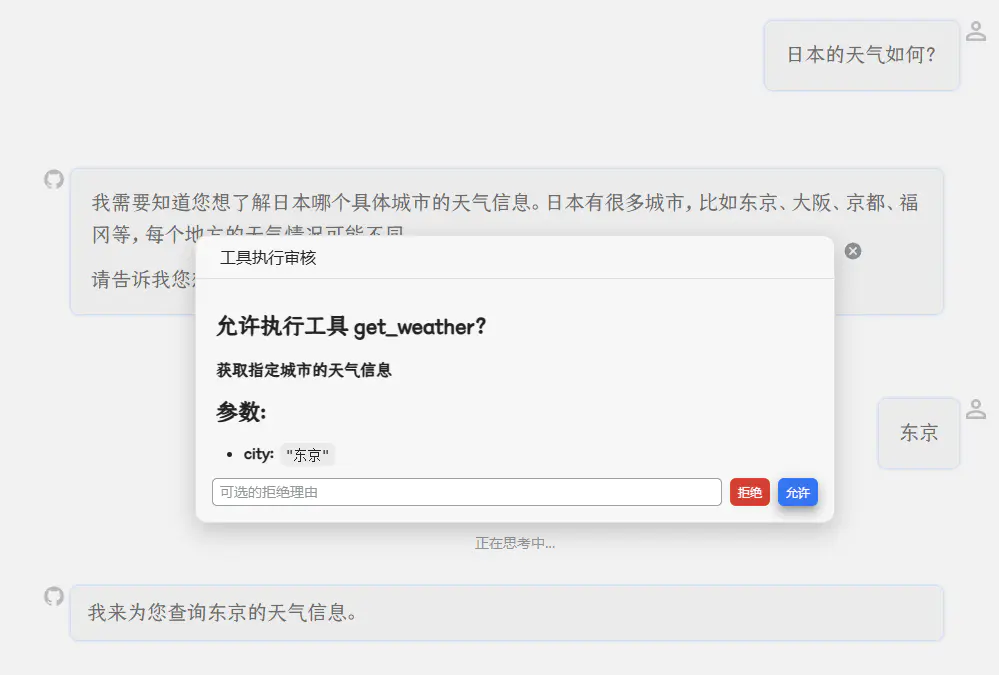
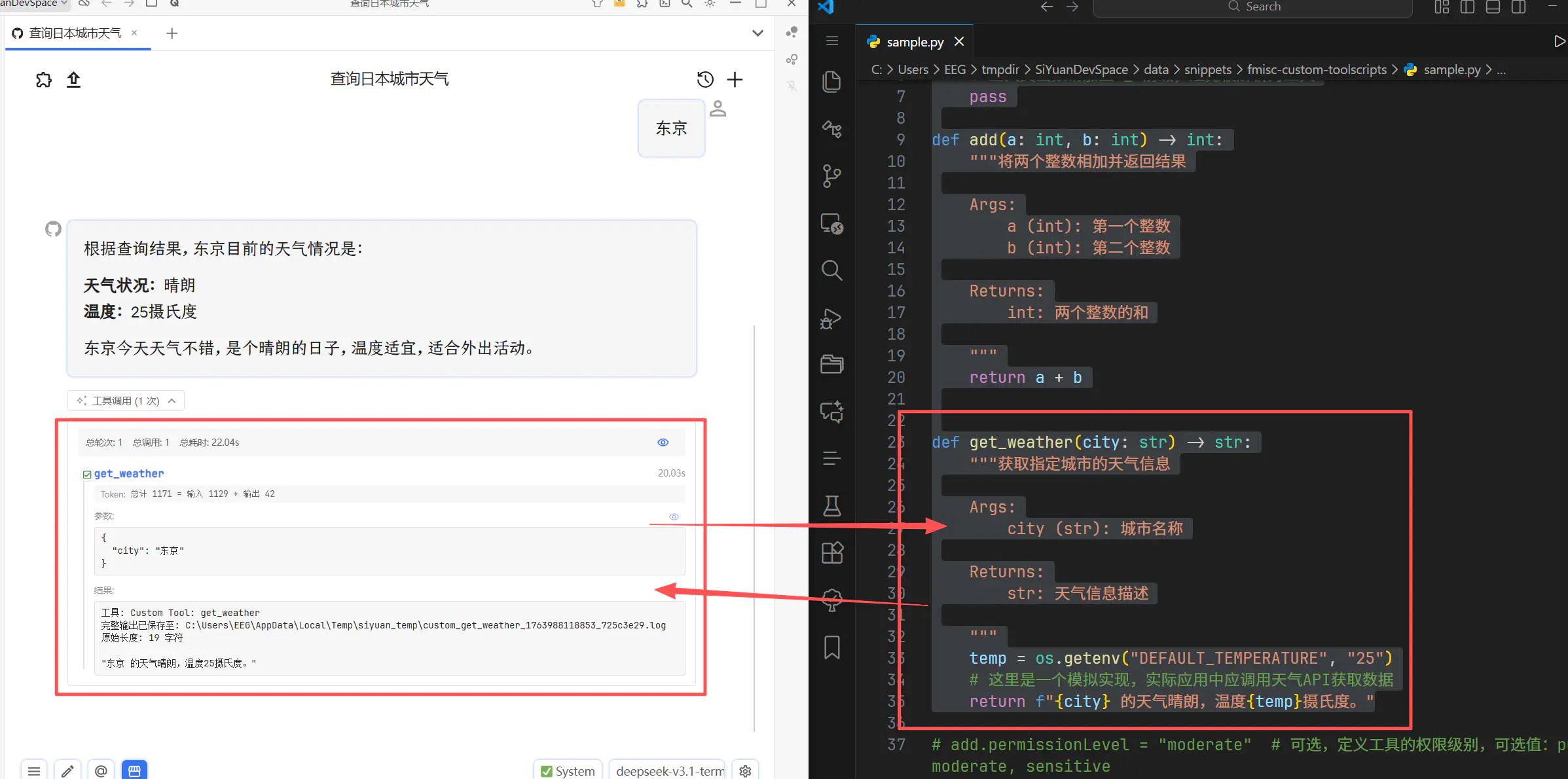
背后是怎么跑的?
核心秘诀
这个功能的实现原理在于:插件会对指定的 Python 文件进行静态分析 (见 public 下的 py2tool.py 脚本),根据函数的 Docstring 和类型标注(Type Hints)自动生成符合 LLM 标准的工具定义(Schema),然后将其动态注入到插件的运行时中。
调用时,插件会把用到的脚本拷贝到临时目录,生成一个 main.py 启动 Python 子进程执行,结果通过标准输出流抓回来。整个过程有点像 Vercel 的 Edge Function——单个脚本无状态、随起随用。
环境变量
Python 工具脚本在运行的时候可能需要依赖特定遍历,比如 API_KEY,特殊设置等等。
可以通过环境变量来获取。
# 尝试从环境变量获取 Token,如果没有则默认为 None
# None 也可以使用,但每小时只能请求 60 次,强烈建议配置 Token
TOKEN = os.getenv('GITHUB_TOKEN')
在插件里配置好对应变量就行:

python 的生态那可太方便了,而且运行我觉得比 nodejs 系还是更轻便一些。
使用案例
以 github_tools 为例,这玩意是 GPT 写的,我就简单调试了一下就能用
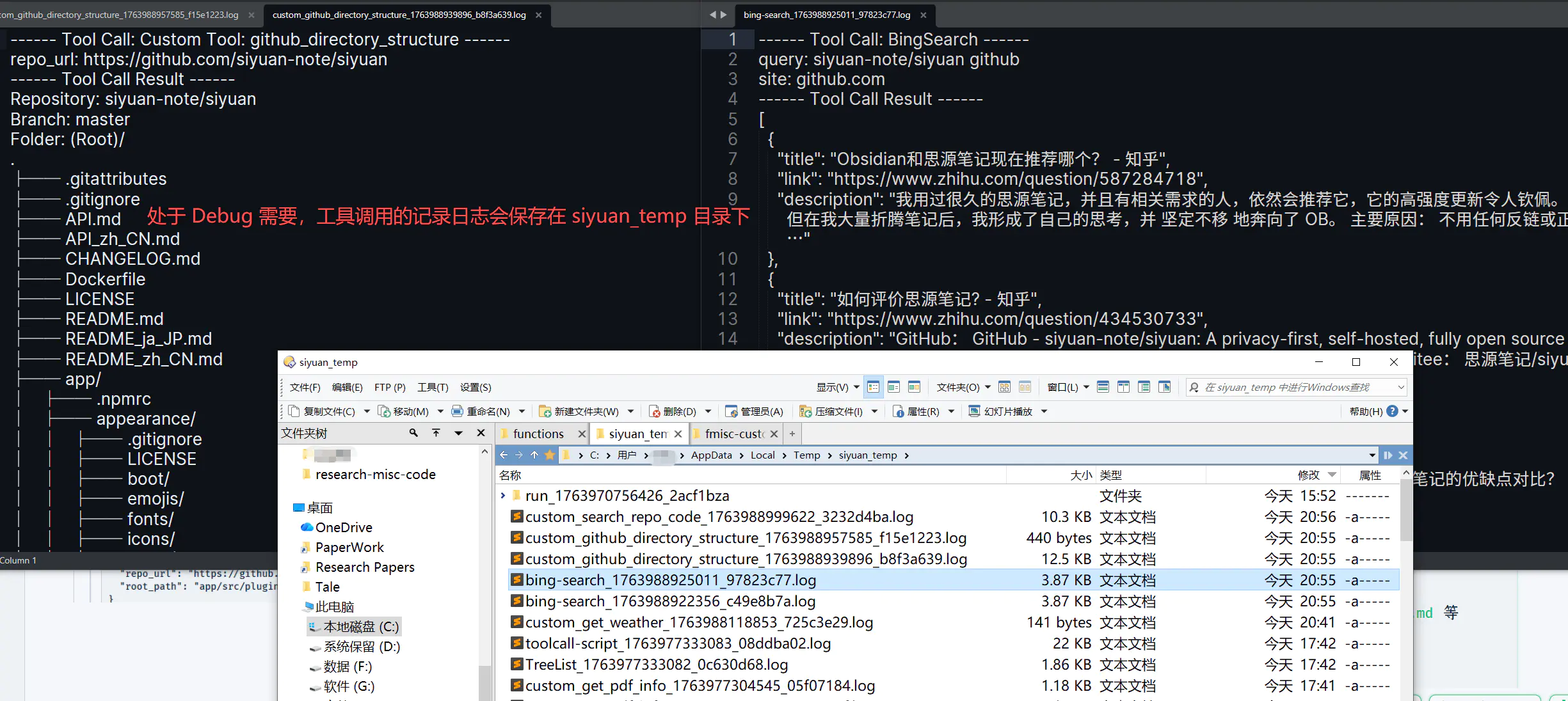
打开 Web 检索和 Github 工具,问一个关于 SiYuan 源码库的问题:

然后就开始哐哐哐调用工具进行分析了
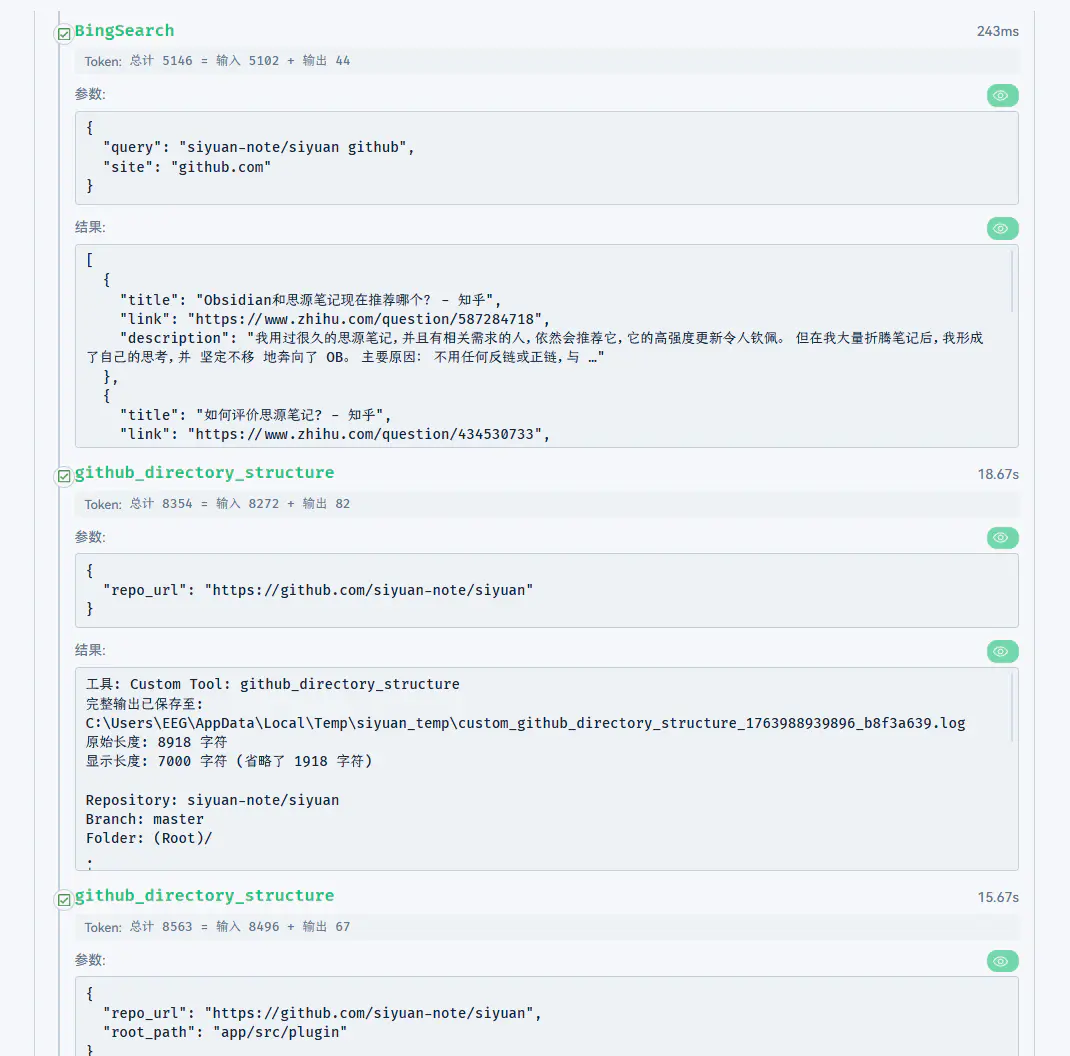
经过五轮调用(BingSearch → BingSearch → github_directory_structure → github_directory_structure → search_repo_code),最后也能给出一个像模像样的回答:

2. ToolCallScript
Tool Call 的槽点
MCP ,或者说所有基于 Tool Call 的功能都有一个巨大的槽点。超级消耗 token !
举个简单例子,我给 deepseek 文件系统访问的工具能力,让他分析一下某个目录下文件的字数行数


结果表现是一团糟,四次工具调用 (我限制了最多四次);先是尝试读取目录下有哪些文件,然后一个一个文件地读入尝试计算字数...
这能完成任务才见鬼了。真让他一个个读取一百多个文件,那钱包直接上天了。
你可能会说"这是因为你没有提供给定文件路径就能计算内部字数的工具"——这就搞笑了,计算字数难道是什么非常复杂高深的能力吗?干脆再杠一点,说之所以 LLM 无法完成指定的任务 X,是因为没有提供能直接一键完成任务 X 的工具算了。
其实问题是这么一回事,传统 tool call 流程是这样的:
- LLM 请求工具
ListDir→ 消耗 1K Token (假设) - 工具返回目录信息(假设有 100 个文件),这些文本全部返回给 LLM
- LLM 分析后决定对 100 个文件逐个调用
ReadFile工具 - 每次调用
ReadFile,文件内容全部读入 LLM → 每个消耗 2K Token (假设) - LLM 汇总所有文件内容,计算字数 → 输出 1K Token (假设)
- 总共消耗:202K Token (假设)
问题出在哪?针对同样长度的文本,无论是困难的语义理解还是简单的字数统计,居然都需要把文本全量喂给 LLM?
大语言模型的 Token 寸土寸金,而你让大模型的内容完全可以是用简单脚本就能解出来的纯垃圾信息。用黄金买垃圾,也是够神奇的解决方案。
问题出在哪?
问题的本质是 LLM 不擅长处理超大量的数据。它用了一种非常均匀的加权来处理所有文本,完全不像人一样会有效分配注意力、分解任务,把困难任务给高成本处理器,把简单任务分配给低成本处理器。
核心症结在于,LLM Tool Call 是高度原子化、弱组织的,不会做任务分配。
LLM 的优点在于解决那些规则模糊的问题(比如语义理解、创意生成),而那些规则完备的问题(比如循环读取文件、字符串处理)明明已经有大量的逻辑化工具可以用,为什么不用呢?
ToolCallScript
简单调研的过程中,看到学界也有些人指出这个问题了。包括工程界 Cursor Copilot 也会有所谓 Planning 模式。
不过我懒得看别人的代码,综合一些观点,再考虑到实现成本,我是这么干的: 设计一个特殊的 Tool ,名叫 ToolCallScript (Tool Orchestration);工具编排脚本。
这个脚本中提供一个特殊的 API: TOOL_CALL(name, args),然后让 LLM 去编写这个脚本,最后把执行结果返回给 LLM。
还是以刚刚的案例为分析,对比一下差别
传统 Tool Call 流程
- LLM 请求工具 ListDIR ---> 消耗 1K Token (假设)
- 返回 ListDIR,发现有 100 个文件
- 对 100 个文件, LLM 调用 100 次工具 ReadFile;每个消耗 2K Token
- 最后汇总结果,输出 1K Token
- 总共消耗 202K Token
而改成让 LLM 写 ToolCallScript ,可能逻辑是这样
LLM 编写脚本,执行如下:
const files = await TOOL_CALL('ListDIR', {dir: dir})
const results = {};
for (const file of files) {
const content = await TOOL_CALL('ReadFile', {path: file.path})
const len = content.len;
results[files] = len;
}
Return results to LLM
由于中间过程的文件内容完全没有返回给 LLM,可能只需要消耗 10K Token 就能完成所有任务了。
在我测试的过程中,意外发现 LLM 比我想象中更能编写 ToolCallScript。本来我推测这种协议没有被训练过,可能很容易出岔子,但就脚本编写而言,LLM 似乎十分擅长。
实际遇到的难点
当然以上是最理想情况,实际过程中还有大坑。
其中最要命的一个坑是,await TOOL_CALL('ListDIR') 返回的可能压根就不是一个结构化数组,而是一大串文本。比如:
- A.txt | Create on 2023-01-01 | Size: 15KB
- B.docx | Create on 2022-12-15 | Size: 45KB
...
最单纯的解决思路是,强制要求每个工具都返回结构化的结果,不过我不太喜欢这种限制太大的做法。
另一种思路是魔法问题用魔法来解决。
具体方案是再加一个 FORMALIZE API。这东西接受两个参数: 一个普通的文本,一个你想要的类型定义格式,然后它就会把前者翻译成后者的形状。
const formated = await FORMALIZE(`
- A.txt | Create on 2023-01-01 | Size: 15KB
- B.docx | Create on 2022-12-15 | Size: 45KB
`, `
{
filename: string;
CreateYear: string; //Should be yyyy format
sizeKB: number; // Be a number without 'KB' suffix.
}[];
`);
>>> formated
[{ "filename": "A.txt", "CreateYear": "2023", "sizeKB": 15 },{ "filename": "B.docx", "CreateYear": "2022", "sizeKB": 45 }]
不难想到 —— 没错 FORMALIZE 本身又是一个 LLM Agent;没办法,处理这种非结构化的数据只能让它上了。
const systemPrompt = `You are a precise data extraction tool. Your task is to convert unstructured text into valid JSON based on a TypeScript type definition. Output ONLY the raw JSON string. Do not include markdown code blocks or explanations. Ensure that the output and be directly parsable by JSON.parse.
Example:
=== Input ===
Target Type:
{
filename: string;
CreateYear: string; //Should be yyyy format
sizeKB: number; // Be a number without 'KB' suffix.
}[];
Input Text:
- A.txt | Create on 2023-01-01 | Size: 15KB
- B.docx | Create on 2022-12-15 | Size: 45KB
=== Output ===
[{ "filename": "A.txt", "CreateYear": "2023", "sizeKB": 15 },{ "filename": "B.docx", "CreateYear": "2022", "sizeKB": 45 }]
`;
const userPrompt = `Target Type:
${typeDescription}
Input Text:
${text}
Extract the data and format it as JSON matching the Target Type.`;
const result = await complete(userPrompt, {
model: store.useModel(store.defaultConfig().utilityModelId || store.defaultModelId()),
systemPrompt: systemPrompt,
option: {
temperature: 0,
stream: false
}
});
注意事项:
- Tool 定义的时候,最好把返回结果的类型也写清楚,不然 LLM 很容易幻觉起来,直接误判了
- 如果 content 文本本身很大,要生成很多内容,也会出现问题,所以这个方法也不完美(后面会讲更激进的方案)
实际操作中,会把这个任务交给“打杂”的低成本模型来完成。

使用案例
这次我们使用 ToolCallScript 看看 deepseek 老师表现如何。
还是刚刚的问题,这次开启新的 TooCallScript 工具组。
顺带提一条:根据我的经验,有些事情如果你大致知道要怎么做、按照什么流程来,就直接和 LLM 说,千万别让他乱猜。当谜语人是没有好下场的。
我们直接和 D 老师说:
分析 C:\Users\EEG\AppData\Local\Temp\siyuan_temp 下,每个文件的行数字数
建议你调用 Tool Call 编排脚本。
首先列举这个目录下所有的文件
然后对每个文件依次读入并计算行数字数
合并起来最后打印到标准流中
注意:列举目录文件返回的结果是纯文本,非结构化可以尝试使用 `FORMALIZE` 提取结构化信息
D 老师很给力,生成了脚本

这次就成功了


依然存在的阴影
但实际上这个测试案例也有风险:发给 D 老师让他结构化提取的 ListDir 结果有一百多个文件,一来一回等了快四分钟,差点触发超时了!
而且把这么多文件发给 D,其实消耗的 token 也不少了。
用 FORMALIZE 方案来解决问题并非完美,同样无法处理输入海量信息的情况。
结果绕来绕去又回到了开始的问题: LLM 太消耗 token 了!
是不是要回到保守的思路,让 Tool 都返回良结构化定义的内容?
我觉得不行。
核心问题在于,我们终归还是需要去处理哪些非结构化文本的。想要把所有的 Tool 都定位为返回结构化数据,不需要解析直接用,还是在过多依赖于人类的先验知识。没有有效解决。
应该允许 Tool 去返回非结构的数据。
那么怎么处理呢?
更加激进的方案:递归任务分解
回过头来,ToolCallScript 的本质是什么?是把一个复杂问题,分解为两个部分:
- 需要 LLM 来解决的复杂任务(语义理解、规划决策)
- 使用简单的程序就能解决的简单任务(循环、字符串处理)
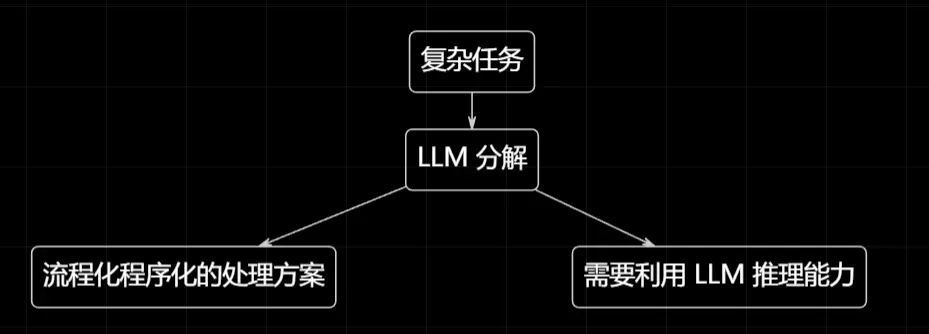
这不禁让我想到了小波分解,一个信号被分解成两部分: 低频信息和高频信息,而对我们更关心的部分可以继续分解。
同样的思路,我们完全可以模仿 ToolCallScript 单层分解的思路,来一个多层递归分解:
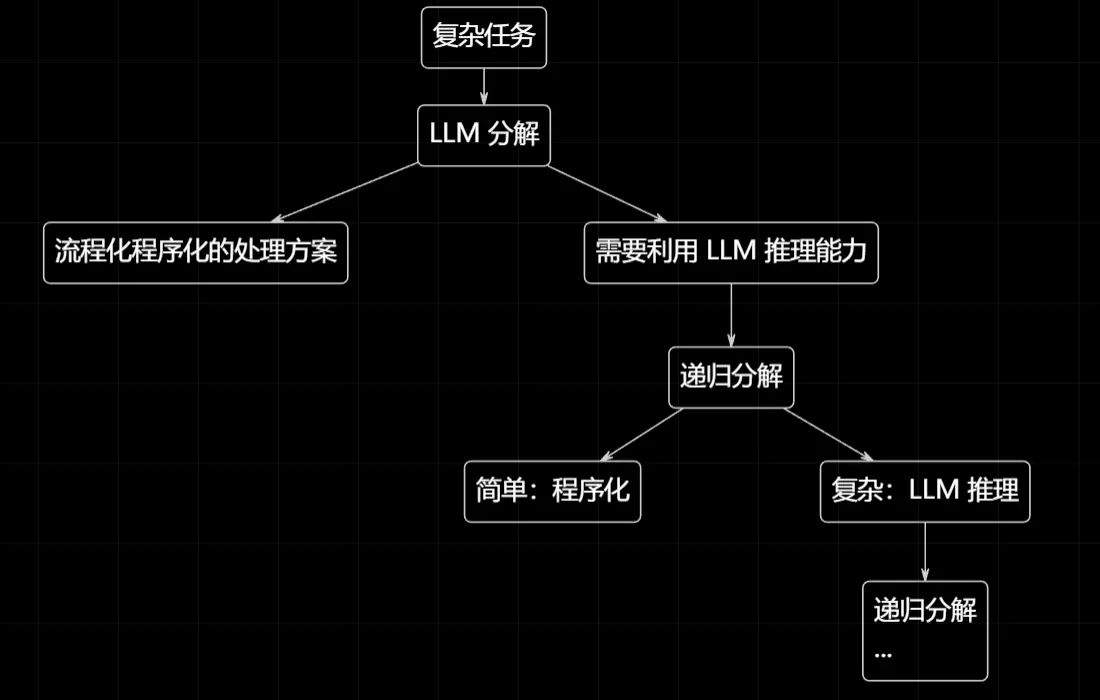
回到这个把非常长的 File List 文本信息解析为结构化数组的任务,其实也可以继续分解啊。

比如先判断这个文件内容有多长,少于一定内容量就直接给 LLM 解析。
多于一定内容量,就进行采样,交给 LLM 查看是否有什么规律。
然后让 LLM 再编写一个 Sub ToolCallScript 按照他发现的规律去分解。
这个 Sub ToolCallScript 又可以套娃调用 LLM....
最后的期待效果就是:只让 LLM 去攻克困难的 、复杂的任务;简单的流程化任务全部交给程序逻辑处理;最大限度提高 Token 的利用效率。
当然具体如何在工程上实现这种想法 ,就是另一回事了,等我有空再研究。
不过问了一下 GPT,业界正常做法一般都是约束 Tool 的结构,来方便解析结果... 🤔
附:浅谈 Claude Skills
这两天空闲下来,把之前一些想法变成代码的过程中,无意也看到了这个新概念。
其实 Tool Call / MCP 浪费 Token 这件事,已经是业界公认了。
Claude 给出的新方案 ;我觉得在底层思路上和我的野路子有相似指出: 就是不要给 LLM 能力,而是要给他元能力,让他有能力去赋能能力。
本质是要求大语言模型更加有策略的去编排自身的行动策略,最终的目的殊途同归都是节省 Token。
Claude Skill 我没有细看设计,不过原理毫不负责地盲猜就是让 Claude 知道怎什么地方能让自己获取新能力,这样不用的时候就不占用 token,需要的时候让他自己加载到自己的运行时当中。
不过对我来讲,启用什么工具组完全可以灵活手动控制,所以对这个概念我还是没啥太大兴趣,就像我之前对 MCP 没啥兴趣一样。
我还是继续自己的野路子吧。
 好多保命声明
好多保命声明
欢迎来到这里!
我们正在构建一个小众社区,大家在这里相互信任,以平等 • 自由 • 奔放的价值观进行分享交流。最终,希望大家能够找到与自己志同道合的伙伴,共同成长。
注册 关于