







第6课 第一个示例HibernateHelloWorld 7
第7课 建立Annotation版本的HellWorld 9
第9课Hibernate的重点学习:Hibernate的对象关系映射. 12
三、 Hibernate.cfg.xml:hbm2ddl.auto 16
六、 ehibernate.cfg.xml : show_sql 17
七、 hibernate.cfg.xml :format_sql 17
十一、 不需要(持久化)psersistence的字段. 18
第12课 使用hibernate工具类将对象模型生成关系模型. 19
一、 Configuration(AnnotationConfiguration) 29
二、 持久化对象(PersistentObject):. 35
(一) 唯一外键关联-单向(unilateralism) 37
(七) 多对一 存储(先存储group(对象持久化状态后,再保存user)):. 50
(七) 导出至数据库(hbmàddl)生成的SQL语句:. 53
八、 关联关系中的CRUD_Cascade_Fetch 63
第19课Hibernate查询(Query Language) 80
四、 工具类Projections提供对查询结果进行统计与分组操作. 91
第22课Query.list与query.iterate(不太重要) 93
第1课 课程内容
1、 HelloWorld
a) Xml
b) Annotction
2、 Hibernate原理模拟-什么是O/RMapping以及为什么要有O/RMapping
3、 常风的O/R框架
4、 Hibernate基础配置
5、 Hibernate核心接口介绍
6、 对象的三种状态
7、 ID生成策略
8、 关系映射
9、 Hibernate查询(HQL)
10、 在Struts基础上继续完美BBS2009
11、 性能优化
12、 补充话题
第2课 Hibernate UML图

第3课 风格
1、 先脉络,后细节
2、 先操作、后原理
3、 重Annotation,轻xml配置文件
a) JPA (可以认为EJB3的一部分)
b) Hibernate– extension
第4课 资源
a) hibernate-distribution-3.3.2.GA-dist.zip
b) hibernate-annotations-3.4.0.GA.zip
c) slf4j-1.5.10.zip (hibernate内部日志用)
2、 hibernatezh_CN文档
3、 hibernateannotateon references
第5课 环境准备
1、 下载hibernate3.3.2
2、 下载hibernate-annotations-3.4.0
3、 注意阅读hibernate compatibility matrix
4、 下载slf4j 1.5.8
第6课 第一个示例Hibernate HelloWorld
1、 建立新的java项目,名为hibernate_0100_HelloWorld
2、 学习建立User-liberary-hibernate,并加入相应的jar包
a) 项目右键-build path-configure build path-add library
b) 选择User-library ,在其中新建library,命名为hibernate
c) 在该library中加入hibernate所需的jar名
i. Hibernatecore
ii. /lib/required
iii. Slf-nopjar
3、 引入mysql的JDBC驱动名
4、 在mysql中建立对应的数据库以及表
a) Create databasehibernate;
b) Usehibernate;
c) Createtable Student (id int primary key, name varchar(20),age int);
5、 建立hibernate配置文件hibernate.cfg.xml
a) 从参考文档中copy
b) 修改对应的数据库连接
c) 注释提暂时不需要的内容
6、 建立Student类
7、 建立Student映射文件Student.hbm.xml
a) 参考文档
8、 将映射文件加入到hibernate.cfg.xml
a) 参考文档
9、 写测试类Main,在Main中对Student对象进行直接的存储测试
public static void main(String[] args) {
Configuration cfg = null;
SessionFactory sf = null;
Session session = null;
Student s = new Student();
s.setId(2);
s.setName("s1");
s.setAge(1);
/*
* org.hibernate.cfg.Configuration类的作用:
* 读取hibernate配置文件(hibernate.cfg.xml或hiberante.properties)的.
* new Configuration()默认是读取hibernate.properties
* 所以使用new Configuration().configure();来读取hibernate.cfg.xml配置文件
*/
cfg = new Configuration().configure();
/*
* 创建SessionFactory
* 一个数据库对应一个SessionFactory
* SessionFactory是线线程安全的。
*/
sf = cfg.buildSessionFactory();
try {
//创建session
//此处的session并不是web中的session
//session只有在用时,才建立concation,session还管理缓存。
//session用完后,必须关闭。
//session是非线程安全,一般是一个请求一个session.
session = sf.openSession();
//手动开启事务(可以在hibernate.cfg.xml配置文件中配置自动开启事务)
session.beginTransaction();
/*
* 保存数据,此处的数据是保存对象,这就是hibernate操作对象的好处,
* 我们不用写那么多的JDBC代码,只要利用session操作对象,至于hibernat如何存在对象,这不需要我们去关心它,
* 这些都有hibernate来完成。我们只要将对象创建完后,交给hibernate就可以了。
*/
session.save(s);
session.getTransaction().commit();
} catch (HibernateException e) {
e.printStackTrace();
//回滚事务
session.getTransaction().rollback();
} finally {
//关闭session
session.close();
sf.close();
}
}
1、 FAQ:
a) 要调用newConfiguration().configure().buildSessionFactory(),而不是省略
* org.hibernate.cfg.Configuration类的作用:
*读取hibernate配置文件(hibernate.cfg.xml或hiberante.properties)的.
*new Configuration()默认是读取hibernate.properties
* 所以使用new Configuration().configure();来读取hibernate.cfg.xml配置文件
注意:在hibernate里的操作都应该放在事务里
第7课 建立Annotation版本的HellWorld
注意:要求hibernate3.0版本以后支持
1、 创建teacher表,create table teacher(id int primary key,namevarchar(20),title varchar(10));
2、 创建Teacher类
public class Teacher {
private int id;
private String name;
private String title;
//设置主键使用@Id
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
}
1、 在hibernate library中加入annotation的jar包
a) Hibernateannotations jar
b) Ejb3persistence jar
c) Hibernatecommon annotations jar
d) 注意文档中没有提到hibernate-common-annotations.jar文件
2、 参考Annotation文档建立对应的注解
import javax.persistence.Entity;
import javax.persistence.Id;
/** @Entity 表示下面的这个Teacher是一个实体类
* @Id 表示主键Id*/
@Entity //***
public class Teacher {
private int id;
private String name;
private String title;
//设置主键使用@Id
@Id //***
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}}
1、 在hibernate.cfg.xml中建立映射<maping class=…/>
<mapping class="com.wjt276.hibernate.model.Teacher"/>
注意:<mapping>标签中使用的是class属性,而不是resource属性,并且使用小数点(.)导航,而不是”/”
2、 参考文档进行测试
public static void main(String[] args) {
Teacher t = new Teacher();
t.setId(1);
t.setName("s1");
t.setTitle("中级");
//注此处并不是使用org.hibernate.cfg.Configuration来创建Configuration
//而使用org.hibernate.cfg.AnnotationConfiguration来创建Configuration,这样就可以使用Annotation功能
Configuration cfg = new AnnotationConfiguration();
SessionFactory sf = cfg.configure().buildSessionFactory();
Session session = sf.openSession();
session.beginTransaction();
session.save(t);
session.getTransaction().commit();
session.close();
sf.close();
}
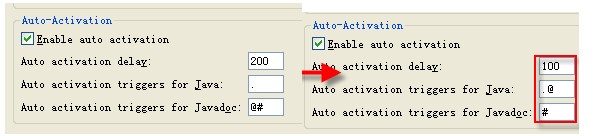
1、 FAQ:@ 后不给提示
解决方法:windows→Proferences→seach “Content Assist”设置Auto-Activation如下:
——————————————————————————————————————————————————————————————————————————————————————————————
第8课 什么是O/R Mapping
一、 定义:
ORM(ObjectRelational Mapping)---是一种为了解决面向对象与关系型数据库存在的互不匹配的现象的技术。简单说:ORM是通过使用描述对象和数据库之间映射的元数据,将Java程序中的对象自动持久化到关系数据中。本质上就是将数据从一种形式转换到另外一种形式。
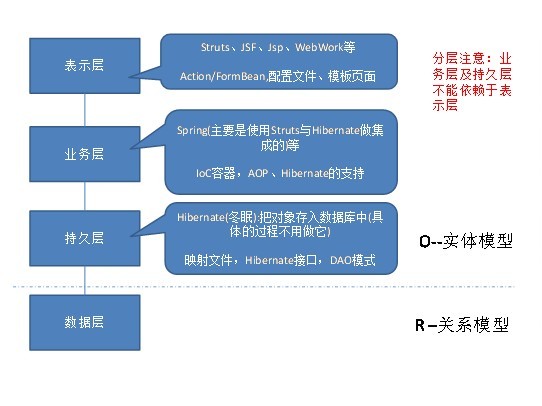
分层后,上层不需要知道下层是如何做了。
分层后,不可以循环依赖,一般是单向依赖。
一、 Hibernate的创始人:
Gavin King
二、 Hibernate做什么:
1、 就是将对象模型(实体类)的东西存入关系模型中,
2、 实体中类对应关系型库中的一个表,
3、 实体类中的一个属性会对应关系型数据库表中的一个列
4、 实体类的一个实例会对应关系型数据库表中的一条记录。
%%将对象数据保存到数据库、将数据库数据读入到对象中%%
OOA---面向对象的分析、面向对象的设计
OOD---设计对象化
OOP---面向对象的开发
阻抗不匹配---例JAVA类中有继承关系,但关系型数据库中不存在这个概念这就是阻抗不匹配。Hibernate可以解决这个问题
三、 Hibernate存在的原因:
1、 解决阻抗不匹配的问题;
2、 目前不存在完整的面向对象的数据库(目前都是关系型数据库);
3、 JDBC操作数据库很繁琐
4、 SQL语句编写并不是面向对象
5、 可以在对象和关系表之间建立关联来简化编程
6、 O/RMapping简化编程
7、 O/RMapping跨越数据库平台
8、 hibernate_0200_OR_Mapping_Simulation
四、 Hibernate的优缺点:
1、 不需要编写的SQL语句(不需要编辑JDBC),只需要操作相应的对象就可以了,就可以能够存储、更新、删除、加载对象,可以提高生产效;
2、 因为使用Hibernate只需要操作对象就可以了,所以我们的开发更对象化了;
3、 使用Hibernate,移植性好(只要使用Hibernate标准开发,更换数据库时,只需要配置相应的配置文件就可以了,不需要做其它任务的操作);
4、 Hibernate实现了透明持久化:当保存一个对象时,这个对象不需要继承Hibernate中的任何类、实现任何接口,只是个纯粹的单纯对象—称为POJO对象(最纯粹的对象—这个对象没有继承第三方框架的任何类和实现它的任何接口)
5、 Hibernate是一个没有侵入性的框架,没有侵入性的框架我们一般称为轻量级框架
6、 Hibernate代码测试方便。
五、 Hibernate使用范围:
1. 针对某一个对象,简单的将它加载、编辑、修改,且修改只是对单个对象(而不是批量的进行修改),这种情况比较适用;
2. 对象之间有着很清晰的关系(例:多个用户属于一个组(多对一)、一个组有多个用户(一对多));
3. 聚集性操作:批量性添加、修改时,不适合使用Hibernate(O/映射框架都不适合使用);
4. 要求使用数据库中特定的功能时不适合使用,因为Hibernate不使用SQL语句;
第9课 Hibernate的重点学习:Hibernate的对象关系映射
一、对象---关系映射模式
l 属性映射;
l 类映射:
l 关联映射:
n 一对一;
n 一对多;
n 多对多。
二、常用的O/R映射框架:
1、 Hibernate
2、 ApacheOJB
3、 JDO(是SUN提出的一套标准—Java数据对象)
4、 Toplink(Orocle公司的)
5、 EJB(2.0X中有CMP;3.0X提出了一套“Java持久化API”---JPA)
6、 IBatis(非常的轻量级,对JDBC做了一个非常非常轻量级的包装,严格说不是O/R映射框架,而是基于SQL的映射(提供了一套配置文件,把SQL语句配置到文件中,再配置一个对象进去,只要访问配置文件时,就可得到对象))
7、 JAP(是SUN公司的一套标准)
a) 意愿统一天下
第10课 模拟Hibernate原理(OR模拟)
我们使用一个项目来完成
功能:有一个配置文件,文件中完成表名与类名对象,字段与类属性对应起来。
测试驱动开发
一、 项目名称
hibernate_0200_OR_Mapping_Simulation
二、 原代码
Test类:
public static void main(String[] args) throws Exception{
Student s = new Student();
s.setId(10);
s.setName("s1");
s.setAge(1);
Session session = new Session();//此Session是我们自己定义的Session
session.save(s);
}
Session类
import java.lang.reflect.Method;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.util.HashMap;
import java.util.Map;
import com.wjt276.hibernate.model.Student;
public class Session {
String tableName = "_Student";
Map<String,String> cfs = new HashMap<String,String>();
String[] methodNames;//用于存入实体类中的get方法数组
public Session(){
cfs.put("_id", "id");
cfs.put("_name", "name");
cfs.put("_age", "age");
methodNames = new String[cfs.size()];
}
public void save(Student s) throws Exception{
String sql = createSQL();//创建SQL串
Class.forName("com.mysql.jdbc.Driver");
Connection conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/hibernate","root","root");
PreparedStatement ps = conn.prepareStatement(sql);
//
for(int i = 0; i < methodNames.length; i++){
Method m = s.getClass().getMethod(methodNames[i]);//返回一个 Method 对象,它反映此 Class 对象所表示的类或接口的指定公共成员方法
Class r = m.getReturnType();//返回一个 Class 对象,该对象描述了此 Method 对象所表示的方法的正式返回类型
if(r.getName().equals("java.lang.String")) {
//对带有指定参数的指定对象调用由此 Method 对象表示的底层方法。
//个别参数被自动解包,以便与基本形参相匹配,基本参数和引用参数都随需服从方法调用转换
String returnValue = (String)m.invoke(s);
ps.setString(i + 1, returnValue);
}
if(r.getName().equals("int")) {
Integer returnValue = (Integer)m.invoke(s);
ps.setInt(i + 1, returnValue);
}
if(r.getName().equals("java.lang.String")) {
String returnValue = (String)m.invoke(s);
ps.setString(i + 1, returnValue);
}
System.out.println(m.getName() + "|" + r.getName());
}
ps.executeUpdate();
ps.close();
conn.close();
}
private String createSQL() {
String str1 = "";
int index = 0;
for(String s : cfs.keySet()){
String v = cfs.get(s);//取出实体类成员属性
v = Character.toUpperCase(v.charAt(0)) + v.substring(1);//将成员属性第一个字符大写
methodNames[index] = "get" + v;//拼实体类成员属性的getter方法
str1 += s + ",";//根据表中字段名拼成字段串
index ++;
}
str1 = str1.substring(0,str1.length() -1);
String str2 = "";
//根据表中字段数,拼成?串
for (int i = 0; i < cfs.size(); i++){ str2 += "?,";}
str2 = str2.substring(0,str2.length() -1);
String sql = "insert into " + tableName + "(" + str1 + ")" + " values (" + str2 + ")";
System.out.println(sql);
return sql;
}}
第11课 Hibernate基础配置
一、 提纲
1、 对应项目:hibernate_0300_BasicConfiguration
2、 介绍MYSQL的图形化客户端
3、 Hibernate.cfg.xml:hbm2ddl.auto
a) 先建表还是先建实体类
4、 搭建日志环境并配置显示DDL语句
5、 搭建Junit环境
a) 需要注意Junit的Bug
6、 ehibernate.cfg.xml: show_sql
7、 hibernate.cfg.xml:format_sql
8、 表名和类名不同,对表名进行配置
a) Annotation:@Table
b) Xml:自己查询
9、 字段名和属性相同
a) 默认为@Basic
b) Xml中不用写column
10、 字段名和属性名不同
a) Annotation:@Column
b) Xml:自己查询
11、 不需要psersistence的字段
a) Annotation:@Transient
b) Xml:不写
12、 映射日期与时间类型,指定时间精度
a) Annotation:@Temporal
b) Xml:指定type
13、 映射枚举类型
a) Annotation:@Enumerated
b) Xml:麻烦
14、 字段映射的位置(field或者get方法)
a) Best practice:保持field和get/set方法的一致
15、 @Lob
16、 课外:CLOB BLOB类型的数据存取
17、 课外:Hibernate自定义数据类型
18、 Hibernate类型
二、 介绍MYSQL的图形化客户端
这样的软件网络很多,主要自己动手做
三、 Hibernate.cfg.xml:hbm2ddl.auto
在SessionFactory创建时,自动检查数据库结构,或者将数据库schema的DDL导出到数据库. 使用 create-drop时,在显式关闭SessionFactory时,将drop掉数据库schema.取值 validate | update | create | create-drop
四、 搭建日志环境并配置显示DDL语句
我们使用slf接口,然后使用log4j的实现。
1、 首先引入log4j的jar包(log4j-1.2.14.jar),
2、 然后再引入slf4j实现LOG4J和适配器jar包(slf4j-log4j12-1.5.8.jar)
3、 最后创建log4j的配置文件(log4j.properties),并加以修改,只要保留
log4j.logger.org.hibernate.tool.hbm2ddl=debug
五、 搭建Junit环境
1、首先引入Junit 类库 jar包 (junit-4.8.1.jar)
2、在项目名上右键→new→Source Folder→输入名称→finish
3、注意,你对哪个包进行测试,你就在测试下建立和那个包相同的包
4、建立测试类,需要在测试的方法前面加入”@Test”
public class TeacherTest {
private static SessionFactory sf = null;
@BeforeClass//表示Junit此类被加载到内存中就执行这个方法
public static void beforClass(){
sf = new AnnotationConfiguration().configure().buildSessionFactory();
}
@Test//表示下面的方法是测试用的。
public void testTeacherSave(){
Teacher t = new Teacher();
t.setId(6);
t.setName("s1");
t.setTitle("中级");
Session session = sf.openSession();
session.beginTransaction();
session.save(t);
session.getTransaction().commit();
session.close();
}
@AfterClass//Junit在类结果时,自动关闭
public static void afterClass(){
sf.close();
}}
六、 ehibernate.cfg.xml : show_sql
输出所有SQL语句到控制台. 有一个另外的选择是把org.hibernate.SQL这个log category设为debug。
取值: true | false
七、 hibernate.cfg.xml :format_sql
在log和console中打印出更漂亮的SQL。
取值: true | false
True样式:
16:32:39,750 DEBUG SchemaExport:377 -
create table Teacher (
id integer not null,
name varchar(255),
title varchar(255),
primary key (id)
)
False样式:
16:33:40,484 DEBUG SchemaExport:377 - create table Teacher (id integer not null, name varchar(255), title varchar(255), primary key (id))八、 表名和类名不同,对表名进行配置
Annotation:使用 @Table(name=”tableName”) 进行注解
例如:
/**
* @Entity 表示下面的这个Teacher是一个实体类
* @Table 表示映射到数据表中的表名,其中的name参数表示"表名称"
* @Id 表示主键Id,一般放在getXXX前面
*/
@Entity
@Table(name="_teacher")
public class Teacher {
[……]
}
Xml:
<class name="Student" table="_student">九、 字段名和属性相同
Annotation:默认为@Basic
注意:如果在成员属性没有加入任何注解,则默认在前面加入了@Basic
Xml中不用写column
十、 字段名和属性名不同
Annotation:使用@Column(name=”columnName”)进行注解
例如:
/**
* @Entity 表示下面的这个Teacher是一个实体类
* @Table 表示映射到数据表中的表名,其中的name参数表示"表名称"
* @Column 表示实体类成员属性映射数据表中的字段名,其中name参数指定一个新的字段名
* @Id 表示主键Id
*/
@Entity
@Table(name="_teacher")
public class Teacher {
private int id;
private String name;
private String title;
//设置主键使用@Id
@Id
public int getId() {
return id;
}
@Column(name="_name")//字段名与属性不同时
public String getName() {
return name;
}
……
Xml:
<property name="name" column="_name"/>十一、 不需要(持久化)psersistence的字段
就是不实体类的某个成员属性不需要存入数据库中
Annotation:使用@Transient 进行注解就可以了。
例如:
@Transient
public String getTitle() {
return title;
}
Xml:不写(就是不需要对这个成员属性进行映射)
十二、 映射日期与时间类型,指定时间精度
Annotation:使用@Temporal(value=TemporalType)来注解表示日期和时间的注解
其中TemporalType有三个值:TemporalType.TIMESTAMP 表示yyyy-MM-dd HH:mm:ss
TemporalType.DATE 表示yyyy-MM-dd
TemporalType.TIME 表示HH:mm:ss
@Temporal(value=TemporalType.DATE)
public Date getBirthDate() {
return birthDate;
}
注意:当使用注解时,属性为value时,则这个属性名可以省略,例如:@Temporal(TemporalType)
Xml:使用type属性指定hibernate类型
<property name="birthDate" type="date"/>注意:hibernate日期时间类型有:date, time, timestamp,当然您也可以使用Java包装类
十二、 映射枚举类型
Annotation:使用@Enumerated(value=EnumType)来注解表示此成员属性为枚举映射到数据库
其中EnumType有二个值:①EnumType.STRING 表示直接将枚举名称存入数据库
②EnumType.ORDINAL 表示将枚举所对应的数值存入数据库
Xml:映射非常的麻烦,先要定义自定义类型,然后再使用这个定义的类型……
第12课 使用hibernate工具类将对象模型生成关系模型
(也就是实体类生成数据库中的表),完整代码如下:
package com.wjt276.hibernate;
import org.hibernate.cfg.AnnotationConfiguration;
import org.hibernate.cfg.Configuration;
import org.hibernate.tool.hbm2ddl.SchemaExport;
/**
* Hibernate工具<br/>
* 将对象模型生成关系模型(将对象生成数据库中的表)
* 把hbm映射文件(或Annotation注解)转换成DDL
* 生成数据表之前要求已经存在数据库
* 注:这个工具类建立好后,以后就不用建立了。以后直接Copy来用。
* @author wjt276
* @version 1.0 2009/10/16
*/
public classExportDB {
public static voidmain(String[] args){
/*org.hibernate.cfg.Configuration类的作用:
*读取hibernate配置文件(hibernate.cfg.xml或hiberante.properties)的.
*new Configuration()默认是读取hibernate.properties
*所以使用newConfiguration().configure();来读取hibernate.cfg.xml配置文件
*/
Configuration cfg = new AnnotationConfiguration().configure();
/*org.hibernate.tool.hbm2ddl.SchemaExport工具类:
*需要传入Configuration参数
*此工具类可以将类导出生成数据库表
*/
SchemaExport export = newSchemaExport(cfg);
/** 开始导出
*第一个参数:script是否打印DDL信息
*第二个参数:export是否导出到数据库中生成表
*/
export.create(true, true);
}}
运行刚刚建立的ExportDB类中的main()方法,进行实际的导出类。
第13课 ID主键生成策略
一、 Xml方式
<id>标签必须配置在<class>标签内第一个位置。由一个字段构成主键,如果是复杂主键<composite-id>标签
被映射的类必须定义对应数据库表主键字段。大多数类有一个JavaBeans风格的属性, 为每一个实例包含唯一的标识。<id> 元素定义了该属性到数据库表主键字段的映射。
<id
name="propertyName" (1)
type="typename" (2)
column="column_name" (3)
unsaved-value="null|any|none|undefined|id_value" (4)
access="field|property|ClassName" (5)
node="element-name|@attribute-name|element/@attribute|.">
<generatorclass="generatorClass"/>
</id>
(1) name (可选): 标识属性的名字(实体类的属性)。
(2) type (可选): 标识Hibernate类型的名字(省略则使用hibernate默认类型),也可以自己配置其它hbernate类型(integer, long, short, float,double, character, byte, boolean, yes_no, true_false)
(2) length(可选):当type为varchar时,设置字段长度
(3) column (可选 - 默认为属性名): 主键字段的名字(省略则取name为字段名)。
(4) unsaved-value (可选 - 默认为一个切合实际(sensible)的值): 一个特定的标识属性值,用来标志该实例是刚刚创建的,尚未保存。 这可以把这种实例和从以前的session中装载过(可能又做过修改--译者注) 但未再次持久化的实例区分开来。
(5) access (可选 - 默认为property): Hibernate用来访问属性值的策略。
如果 name属性不存在,会认为这个类没有标识属性。
unsaved-value 属性在Hibernate3中几乎不再需要。
还有一个另外的<composite-id>定义可以访问旧式的多主键数据。 我们强烈不建议使用这种方式。
<generator>元素(主键生成策略)
主键生成策略是必须配置
用来为该持久化类的实例生成唯一的标识。如果这个生成器实例需要某些配置值或者初始化参数, 用<param>元素来传递。
<id name="id"type="long" column="cat_id">
<generator class="org.hibernate.id.TableHiLoGenerator">
<param name="table">uid_table</param>
<param name="column">next_hi_value_column</param>
</generator>
</id>
所有的生成器都实现org.hibernate.id.IdentifierGenerator接口。 这是一个非常简单的接口;某些应用程序可以选择提供他们自己特定的实现。当然, Hibernate提供了很多内置的实现。下面是一些内置生成器的快捷名字:
increment
用于为long, short或者int类型生成 唯一标识。只有在没有其他进程往同一张表中插入数据时才能使用。 在集群下不要使用。
identity
对DB2,MySQL, MS SQL Server,Sybase和HypersonicSQL的内置标识字段提供支持。 返回的标识符是long, short 或者int类型的。 (数据库自增)
sequence
在DB2,PostgreSQL, Oracle, SAPDB, McKoi中使用序列(sequence), 而在Interbase中使用生成器(generator)。返回的标识符是long, short或者 int类型的。(数据库自增)
hilo
使用一个高/低位算法高效的生成long, short 或者 int类型的标识符。给定一个表和字段(默认分别是 hibernate_unique_key和next_hi)作为高位值的来源。 高/低位算法生成的标识符只在一个特定的数据库中是唯一的。
seqhilo
使用一个高/低位算法来高效的生成long, short 或者 int类型的标识符,给定一个数据库序列(sequence)的名字。
uuid
用一个128-bit的UUID算法生成字符串类型的标识符, 这在一个网络中是唯一的(使用了IP地址)。UUID被编码为一个32位16进制数字的字符串,它的生成是由hibernate生成,一般不会重复。
UUID包含:IP地址,JVM的启动时间(精确到1/4秒),系统时间和一个计数器值(在JVM中唯一)。 在Java代码中不可能获得MAC地址或者内存地址,所以这已经是我们在不使用JNI的前提下的能做的最好实现了
guid
在MS SQL Server 和 MySQL 中使用数据库生成的GUID字符串。
native
根据底层数据库的能力选择identity,sequence 或者hilo中的一个。(数据库自增)
assigned
让应用程序在save()之前为对象分配一个标示符。这是 <generator>元素没有指定时的默认生成策略。(如果是手动分配,则需要设置此配置)
select
通过数据库触发器选择一些唯一主键的行并返回主键值来分配一个主键。
foreign
使用另外一个相关联的对象的标识符。通常和<one-to-one>联合起来使用。
二、 annotateon方式
使用@GeneratedValue(strategy=GenerationType)注解可以定义该标识符的生成策略
Strategy有四个值:
① 、AUTO- 可以是identity column类型,或者sequence类型或者table类型,取决于不同的底层数据库.
相当于native
② 、TABLE- 使用表保存id值
③ 、IDENTITY- identity column
④ 、SEQUENCE- sequence
注意:auto是默认值,也就是说没有后的参数则表示为auto
1、AUTO默认
@Id
@GeneratedValue
public int getId() {
return id;
}
或
@Id
@GeneratedValue(strategy=GenerationType.AUTO)
public int getId() {
return id;
}
1、 对于mysql,使用auto_increment
2、 对于oracle使用hibernate_sequence(名称固定)
2、IDENTITY
@Id
@GeneratedValue(strategy=GenerationType.IDENTITY)
public int getId() {
return id;
}
对DB2,MySQL, MS SQL Server,Sybase和HypersonicSQL的内置标识字段提供支持。 返回的标识符是long, short 或者int类型的。 (数据库自增)
注意:此生成策略不支持Oracle
3、SEQUENCE
@Id
@GeneratedValue(strategy=GenerationType.SEQUENCE)
public int getId() {
return id;
}
在DB2,PostgreSQL,Oracle, SAP DB, McKoi中使用序列(sequence), 而在Interbase中使用生成器(generator)。返回的标识符是long, short或者 int类型的。(数据库自增)
注意:此生成策略不支持MySQL
4、为Oracle指定定义的Sequence
a)、首先需要在实体类前面申明一个Sequence如下:
方法:@SequenceGenerator(name="SEQ_Name",sequenceName="SEQ_DB_Name")
参数注意:SEQ_Name:表示为申明的这个Sequence指定一个名称,以便使用
SEQ_DB_Name:表示为数据库中的Sequence指定一个名称。
两个参数的名称可以一样。
@Entity
@SequenceGenerator(name="teacherSEQ",sequenceName="teacherSEQ_DB")
public class Teacher {
……
}
b)、然后使用@GeneratedValue注解
方法:@GeneratedValue(strategy=GenerationType.SEQUENCE,generator="SEQ_Name")
参数:strategy:固定为GenerationType.SEQUENCE
Generator:在实体类前面申明的sequnce的名称
@Entity
@SequenceGenerator(name="teacherSEQ",sequenceName="teacherSEQ_DB")
public class Teacher {
private int id;
@Id
@GeneratedValue(strategy=GenerationType.SEQUENCE,generator="teacherSEQ")
public int getId() {
return id;
}}
5、TABLE - 使用表保存id值
原理:就是在数据库中建立一个表,这个表包含两个字段,一个字段表示名称,另一个字段表示值。每次在添加数据时,使用第一个字段的名称,来取值作为添加数据的ID,然后再给这个值累加一个值再次存入数据库,以便下次取出使用。
Table主键生成策略的定义:
@javax.persistence.TableGenerator(
name="Teacher_GEN", //生成策略的名称
table="GENERATOR_TABLE", //在数据库生成表的名称
pkColumnName = "pk_key", //表中第一个字段的字段名 类型为varchar,key
valueColumnName = "pk_value", //表中第二个字段的字段名 int ,value
pkColumnValue="teacher", //这个策略中使用该记录的第一个字段的值(key值)
initialValue = 1, //这个策略中使用该记录的第二个字段的值(value值)初始化值
allocationSize=1 //每次使用数据后累加的数值
)
这样执行后,会在数据库建立一个表,语句如下:
create tableGENERATOR_TABLE (pk_key varchar(255),pk_value integer )
结构:

并且表建立好后,就插入了一个记录,如下:
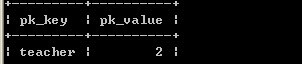
注:这条记录的pk_value值为2,是因为刚刚做例程序时,已经插入一条记录了。初始化时为1。
使用TABLE主键生成策略:
@Entity
@javax.persistence.TableGenerator(
name="Teacher_GEN", //生成策略的名称
table="GENERATOR_TABLE", //在数据库生成表的名称
pkColumnName = "pk_key", //表中第一个字段的字段名 类型为varchar,key
valueColumnName = "pk_value", //表中第二个字段的字段名 int ,value
pkColumnValue="teacher", //这个策略中使用该记录的第一个字段的值(key值)
initialValue = 1, //这个策略中使用该记录的第二个字段的值(value值)初始化值
allocationSize=1 //每次使用数据后累加的数值
)
public class Teacher {
private int id;
@Id
@GeneratedValue(strategy=GenerationType.TABLE,generator="Teacher_GEN")
public int getId() {
return id;}}
注意:这样每次在添加Teacher记录时,都会先到GENERATOR_TABLE表取pk_key=teacher的记录后,使用pk_value值作为记录的主键。然后再给这个pk_value字段累加1,再存入到GENERATOR_TABLE表中,以便下次使用。
这个表可以给无数的表作为主键表,只是添加一条记录而以(需要保证table、pkColumnName、valueColumnName三个属性值一样就可以了。),这个主键生成策略可以跨数据库平台。
三、 联合主键
复合主键(联合主键):多个字段构成唯一性。
1、xml方式
a) 实例场景:核算期间
// 核算期间
public class FiscalYearPeriod {
private int fiscalYear; //核算年
private int fiscalPeriod; //核算月
private Date beginDate; //开始日期
private Date endDate; //结束日期
private String periodSts; //状态
public int getFiscalYear() {
return fiscalYear;
}
public void setFiscalYear(int fiscalYear) {
this.fiscalYear = fiscalYear;
}
public int getFiscalPeriod(){ return fiscalPeriod;}
public void setFiscalPeriod(int fiscalPeriod) {
this.fiscalPeriod =fiscalPeriod;
}
public DategetBeginDate() { return beginDate;}
public void setBeginDate(DatebeginDate) { this.beginDate = beginDate; }
public Date getEndDate(){ return endDate;}
public void setEndDate(DateendDate) { this.endDate = endDate; }
public StringgetPeriodSts() { return periodSts;}
public voidsetPeriodSts(String periodSts) { this.periodSts = periodSts;}
}
复合主键的映射,一般情况把主键相关的属性抽取出来单独放入一个类中。而这个类是有要求的:必需实现序列化接口(java.io.Serializable)(可以保存到磁盘上),为了确定这个复合主键类所对应对象的唯一性就会产生比较,对象比较就需要复写对象的hashCode()、equals()方法(复写方法如下图片),然后在类中引用这个复合主键类

b) 复合主键类:
复合主键必需实现java.io.Serializable接口
public class FiscalYearPeriodPKimplements java.io.Serializable {
private int fiscalYear;//核算年
private int fiscalPeriod;//核算月
public int getFiscalYear() {
return fiscalYear;
}
public void setFiscalYear(int fiscalYear) {
this.fiscalYear = fiscalYear;
}
public int getFiscalPeriod(){
return fiscalPeriod;
}
public void setFiscalPeriod(int fiscalPeriod) {
this.fiscalPeriod =fiscalPeriod;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime* result + fiscalPeriod;
result = prime* result + fiscalYear;
return result;
}
@Override
public boolean equals(Object obj){
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() !=obj.getClass())
return false;
FiscalYearPeriodPKother = (FiscalYearPeriodPK) obj;
if (fiscalPeriod != other.fiscalPeriod)
return false;
if (fiscalYear != other.fiscalYear)
return false;
return true;
}}
c) 实体类:(中引用了复合主键类)
public class FiscalYearPeriod{
private FiscalYearPeriodPK fiscalYearPeriodPK;//引用 复合主键类
private Date beginDate;//开始日期
private Date endDate;//结束日期
private String periodSts;//状态
public FiscalYearPeriodPK getFiscalYearPeriodPK() {
return fiscalYearPeriodPK;
}
public void setFiscalYearPeriodPK(FiscalYearPeriodPKfiscalYearPeriodPK) {
this.fiscalYearPeriodPK = fiscalYearPeriodPK;
}
………………
d) FiscalYearPeriod.hbm.xml映射文件
<hibernate-mapping>
<class name="com.bjsxt.hibernate.FiscalYearPeriod"table="t_fiscal_year_period">
<composite-id name="fiscalYearPeriodPK">
<key-property name="fiscalYear"/>
<key-property name="fiscalPeriod"/>
</composite-id>
<property name="beginDate"/>
<property name="endDate"/>
<property name="periodSts"/>
</class>
</hibernate-mapping>
e) 导出数据库输出SQL语句:
create table t_fiscalYearPeriod (fiscalYear integer not null, fiscalPeriodinteger not null, beginDate datetime, endDate datetime, periodSts varchar(255),primary key (fiscalYear, fiscalPeriod))//实体映射到数据就是两个字段构成复合主键
f) 数据库表结构:
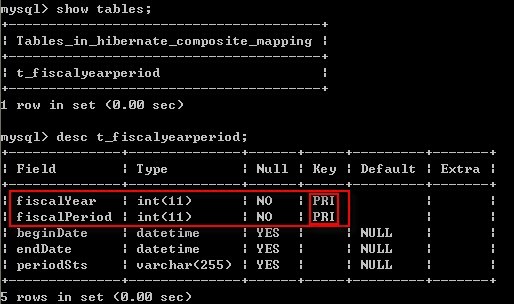
g) 复合主键关联映射数据存储:
session =HibernateUtils.getSession();
tx =session.beginTransaction();
FiscalYearPeriod fiscalYearPeriod = new FiscalYearPeriod();
//构造复合主键
FiscalYearPeriodPK pk = new FiscalYearPeriodPK();
pk.setFiscalYear(2009);
pk.setFiscalPeriod(11);
fiscalYearPeriod.setFiscalYearPeriodPK(pk);//为对象设置复合主键
fiscalYearPeriod.setEndDate(new Date());
fiscalYearPeriod.setBeginDate(new Date());
fiscalYearPeriod.setPeriodSts("Y");
session.save(fiscalYearPeriod);
h) 执行输出SQL语句:
Hibernate: insert into t_fiscalYearPeriod (beginDate, endDate, periodSts,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 88
88











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









