







假设现在有一个日志文件test.log,文件中的内容如下:
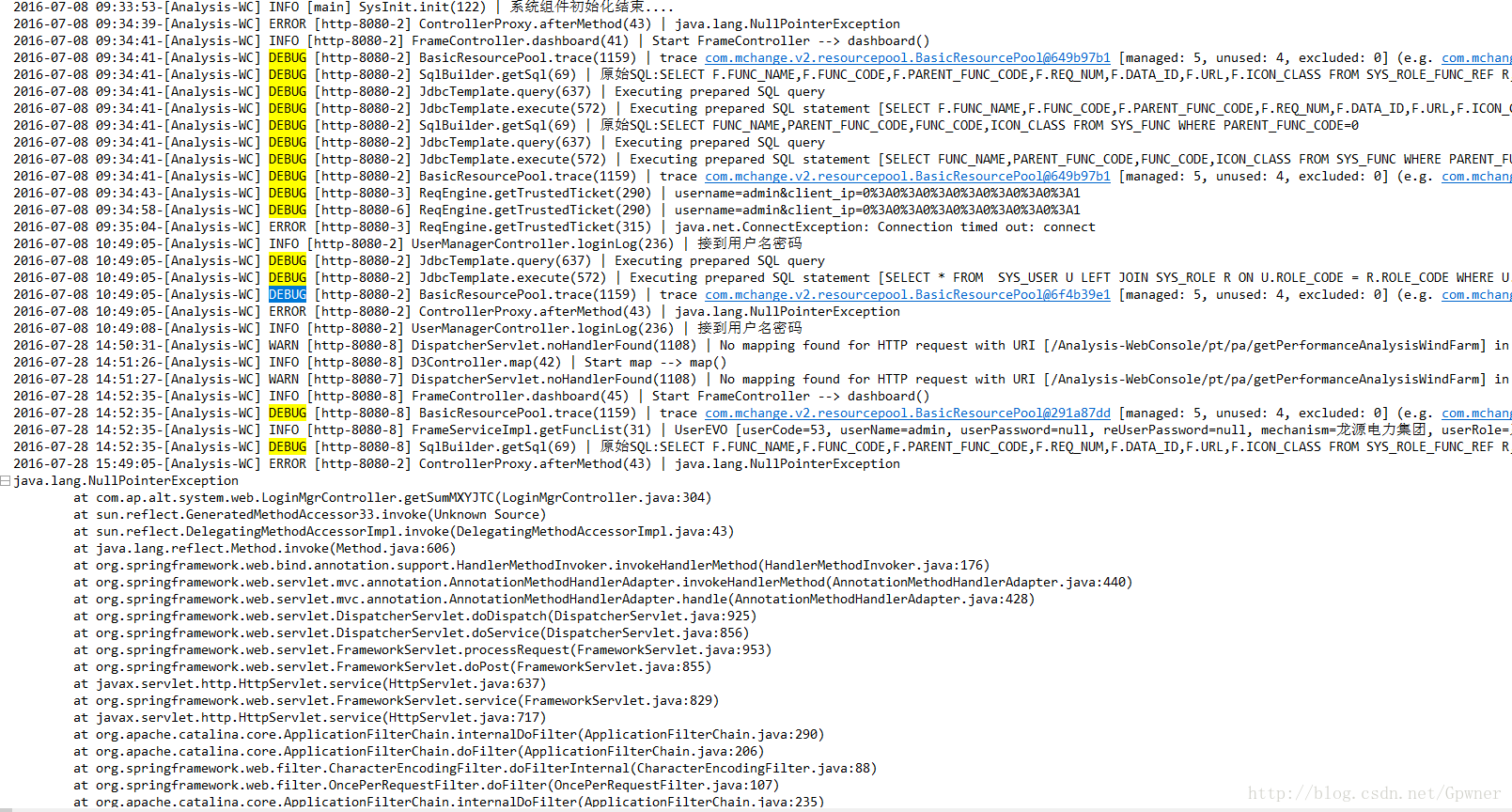
现在的需求是需要将日志通过Flume收集上来,在HDFS进行分区,比如
2016-07-08/INFO
2016-07-08/DEBUG
2016-07-08/WARN
2016-07-08/ERROR
方法一:自定义Source
在GitHub上看到有人自定义了Source,其核心思想是:
如果当前有两行记录,如果两行记录都是“正常”的日志信息,比如:
2016-07-08 09:33:53-[Analysis-WC] INFO [main] FormulaContextUtil.init(68) | into FormulaContextUtil.init method begin ....
2016-07-08 09:33:53-[Analysis-WC] INFO [main] FormulaContextUtil.init(133) | FormulaContextUtil.init method end ....则单独将每一行当做一个Event,传递;
当连续的两条记录诸如这样的形式:
2016-07-28 15:49:05-[Analysis-WC] ERROR [http-8080-2] ControllerProxy.afterMethod(43) | java.lang.NullPointerException
java.lang.NullPointerException
at com.ap.alt.system.web.LoginMgrController.getSumMXYJTC(LoginMgrController.java:304)则将下一行日志合并到上一个Event中;
其核心代码是:
while ((line = reader.readLine()) != null) {
synchronized (eventList) {
//multiline setting start
Matcher m = pattern.matcher(line);
if (m.find()) {
//匹配上之后把上次的event放入evenlist
if (buffer.size() != 0) {
//write to body
sourceCounter.incrementEventReceivedCount();
String total = "";
for (int i = 0; i < buffer.size(); ++i) {
total += buffer.get(i);
}
eventList.add(EventBuilder.withBody(total.getBytes(charset)));
if (eventList.size() >= bufferCount || timeout()) {
flushEventBatch(eventList);
}
buffer.clear();
}
buffer.add(line);
} else {
buffer.add(System.getProperty("line.separator", "\n") + line);
}
//multiline setting end
}
}Flume配置文件
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type =MultiLineExecSource
a1.sources.r1.command = tail -100 /root/tmp/logs/test.log
a1.sources.r1.channels = c1
a1.sources.r1.lineStartRegex = ^\\d\\d\\d\\d-\\d\\d-\\d\\d\\s\\d\\d:\\d\\d:\\d\\d
a1.sources.r1.interceptors=i1
a1.sources.r1.interceptors.i1.type=regex_extractor
a1.sources.r1.interceptors.i1.regex =^(\\d\\d\\d\\d-\\d\\d-\\d\\d).\\d\\d:\\d\\d:\\d\\d.{14}.(INFO|DEBUG|ERROR|WARN)
a1.sources.r1.interceptors.i1.serializers = s1 s2
a1.sources.r1.interceptors.i1.serializers.s1.name = date
a1.sources.r1.interceptors.i1.serializers.s2.name = time
# Use a channel which buffers events inmemory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sinks.k1.channel = c1
a1.sinks.k1.type= hdfs
a1.sinks.k1.channel= c1
a1.sinks.k1.hdfs.path= hdfs://172.17.11.105:9000/flume/%{date}/%{time}
a1.sinks.k1.hdfs.rollSize=5120
a1.sinks.k1.hdfs.rollCount=50000
a1.sinks.k1.hdfs.fileType=DataStream具体的代码可以到我的GitHub上下载
方法二:自定义拦截器
这是我自己想的方法,首先我修改的是RegexExtractorInterceptor这个拦截器
核心思想是当正则表达式匹配上Event的时候,使用RegexExtractorInterceptor类的一个静态属性记录下来这个Event的头部信息(也就是诸如2016-07-08/ERROR的匹配到的信息),然后当下一条记录不匹配的时候,显然,这行日志是属于上一条记录的,比如:
2016-07-28 15:49:05-[Analysis-WC] ERROR [http-8080-2] ControllerProxy.afterMethod(43) | java.lang.NullPointerException
java.lang.NullPointerException
at com.ap.alt.system.web.LoginMgrController.getSumMXYJTC(LoginMgrController.java:304)中的最后几行实际上都是属于第一条日志的,Java的类变量正好能解决我的这个需求。
核心代码:
public class RegexExtractorInterceptor implements Interceptor {
//这是我添加的类静态属性,其他的代码省略
private static Map<String, String> values = new HashMap<String, String>();
//......省略
public Event intercept(Event event) {
//.......省略
if (matcher.find()) {
//.....省略
headers.put(serializer.headerName, serializer.serializer.serialize(matcher.group(groupIndex)));
values.put(serializer.headerName, serializer.serializer.serialize(matcher.group(groupIndex)));
}
} else {
//添加的代码
for (Map.Entry<String, String> en : values.entrySet()) {
headers.put(en.getKey(), en.getValue());
}
}
return event;
}
Flume配置文件:
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -100 /root/tmp/logs/test.log
a1.sources.r1.channels = c1
a1.sources.r1.interceptors=i1
a1.sources.r1.interceptors.i1.type=interceptor.RegexExtractorInterceptor$Builder
a1.sources.r1.interceptors.i1.regex =^(\\d\\d\\d\\d-\\d\\d-\\d\\d).\\d\\d:\\d\\d:\\d\\d.{14}.(INFO|DEBUG|ERROR|WARN)
a1.sources.r1.interceptors.i1.serializers = s1 s2
a1.sources.r1.interceptors.i1.serializers.s1.name = date
a1.sources.r1.interceptors.i1.serializers.s2.name = time
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events inmemory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
a1.sinks.k1.type= hdfs
a1.sinks.k1.channel= c1
a1.sinks.k1.hdfs.path= hdfs://172.17.11.105:9000/flume/%{date}/%{time}
a1.sinks.k1.hdfs.rollSize=5120
a1.sinks.k1.hdfs.rollCount=50000
a1.sinks.k1.hdfs.fileType=DataStream
来个效果图:

两个方法的代码、Jar包、配置文件已经上传到我的GitHub,备忘














 2113
2113











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









