
本文档旨在系统性介绍如何基于阿里云日志服务及其采集组件LoongCollector,实现Kubernetes容器日志的高效采集、处理与分析。文档内容聚焦于核心原理、关键流程、选型建议和最佳实践,并作为具体操作文档的引导。
功能特点
日志服务在Kubernetes容器日志采集中提供以下核心能力:
多源日志支持
日志类型:标准输出信息(stdout)、标准错误信息(stderr)与容器文本文件日志。
精细化容器过滤
通过Namespace名称、Pod名称、容器名称、容器Label或环境变量来指定/排除采集的容器。
复杂日志处理能力
智能元数据关联
上报容器日志时自动关联Meta信息(例如容器名、镜像、Pod、Namespace、环境变量等)。
可靠性保障
checkpoint机制通过记录当前采集位置确保日志完整性。
容器停止时的日志处理:对不同运行时提供不同的容器停止处理策略。
使用限制
容器运行时:仅支持Docker与Containerd。
Docker:
通过/run/docker.sock访问,请确保该路径存在且具备访问权限。
目前标准输出采集仅支持JSON类型的日志驱动。
只支持overlay、overlay2两种存储驱动,其他存储驱动需将日志所在目录通过数据卷挂载为临时目录。
Containerd:
通过/run/containerd/containerd.sock访问,请确保该路径存在且具备访问权限。
多行日志限制:
为保证多行组成的一条日志不因输出延迟而被分割成多条,采集的最后一条日志默认都会缓存一段时间。默认缓存时间为3秒,可通过
BeginLineTimeoutMs参数修改,但不能低于1000(毫秒),否则容易出现误判。标准输出每条日志最大值:
默认值:524288(512 KB),最大值:8388608(8 MB)。 如果您的单条日志超过524288 Byte,可给LoongCollecor容器添加环境变量
max_read_buffer_size进行修改。
核心概念
Kubernetes:Kubernetes (K8s) 是一个开源的容器编排平台,用于自动化部署、扩展和管理容器化应用程序,是现代化云原生应用开发和运维的核心基础设施。
标准输出、标准错误与文本文件日志:标准输出(stdout)是程序正常运行时打印的信息(例如:业务日志、操作记录),默认输出到终端并被容器引擎捕获存储;标准错误(stderr)是程序错误或警告信息(例如:异常堆栈、启动失败原因),同样被容器引擎捕获存储,可与stdout混合输出;文本文件日志是应用主动写入文件的日志(例如:Nginx的
access.log、自定义日志文件),直接写入容器内部文件系统,随容器销毁而销毁,可通过Volumn持久化。checkpoint机制:checkpoint用于记录日志服务当前采集到文件的具体位置,默认在
/tmp/logtail_checkpoint中保存。用于保障LoongCollector重启或节点宕机等异常情况下日志采集的可靠性。LoongCollector(Logtail):阿里云自研的高性能日志采集器,支持DaemonSet和Sidecar的Kubernetes部署模式。其中LoongCollector是Logtail的升级版,兼容Logtail的所有功能。
Kubernetes CRD:CRD是Kubernetes 的一种机制,允许用户自定义资源并创建实例进行配置,日志服务提供的自定义资源类型为AliyunPipelineConfig。
采集配置:用于定义采集日志的类型,采集路径、有效日志的筛选,日志内容的解析、存储到日志服务的位置等规则,详情可参考什么是LoongCollector采集配置。
解析插件:在采集配置的处理插件配置中使用,日志服务提供了众多用于结构化、切分、过滤、脱敏日志内容的处理单元,支持正则、分隔符、JSON、多行等多种处理模式。
日志采集原理
DaemonSet模式原理
在集群的每个Node节点上部署一个 LoongCollector,负责采集该节点上所有容器的日志;特点:运维简单、资源占用少、配置方式灵活;但是隔离性较弱。
在DaemonSet模式中,Kubernetes集群确保每个节点(Node)只运行一个LoongCollector容器,用于采集当前节点内所有容器(Containers)的日志。
当新节点加入集群时,Kubernetes集群会自动在新节点上创建LoongCollector容器;当节点退出集群时,Kubernetes集群会自动销毁当前节点上的LoongCollector容器。通过DaemonSet的自动扩缩容机制以及标识型机器组,无需手动管理LoongCollector实例。

Sidecar模式原理
每个 Pod 中伴随业务容器注入一个 LoongCollector Sidecar容器,并将业务容器的日志目录通过K8s的Volume机制(如emptyDir、hostPath、PVC等)挂载为共享卷。这样,日志文件会同时出现在业务容器和Sidecar容器的挂载路径下,LoongCollector就能直接读取这些日志文件;特点:多租户隔离性好、性能好;但资源占用较多,配置与维护较复杂。
在Sidecar模式中,每个容器组(Pod)运行一个LoongCollector容器,用于采集当前容器组(Pod)所有容器(Containers)的日志。不同Pod的日志采集相互隔离。
为了采集同一Pod中其他容器的日志文件,需要通过共享存储卷的方式来完成,需要将同一份存储卷分别挂载到业务容器和LoongCollector容器。
当一个节点上的 Pod 数据量异常庞大,远超出 Daemonset 的采集性能上限时,Sidecar模式允许我们为LoongCollector分配特定的资源,从而提升其日志采集的性能和稳定性。
在 Serverless 容器中缺乏节点的概念,传统的 Daemonset 部署模式无法应用。此时,SideCar 模式能够有效地与无服务器架构结合,保证日志采集过程的灵活性和适应性。

容器发现原理
LoongCollector容器若要采集其他容器的日志,必须发现和确定哪些容器正在运行,这个过程称为容器发现。
在容器发现阶段,LoongCollector容器不与Kubernetes集群的kube-apiserver进行通信,而是直接和节点上的容器运行时守护进程(Container Runtime Daemon)进行通信,从而获取当前节点上的所有容器信息,避免容器发现对集群kube-apiserver产生压力。
LoongCollector支持通过访问位于宿主机上容器运行时(Docker Engine/ContainerD)的 sock 获取容器的上下文信息,支持Namespace名称、Pod名称、Pod标签、容器环境变量等条件指定或排除采集相应容器的日志。
标准输出采集
根据容器元信息自动识别不同容器运行时(如Docker、Containerd)的API或日志驱动,不需要额外手动配置,直接读取所有容器的标准输出流,无需访问容器内的文件系统。
在采集容器的标准输出时,会定期将采集的点位信息保存到checkpoint文件中。如果LoongCollector停止后再次启动,会从上一次保存的点位开始采集。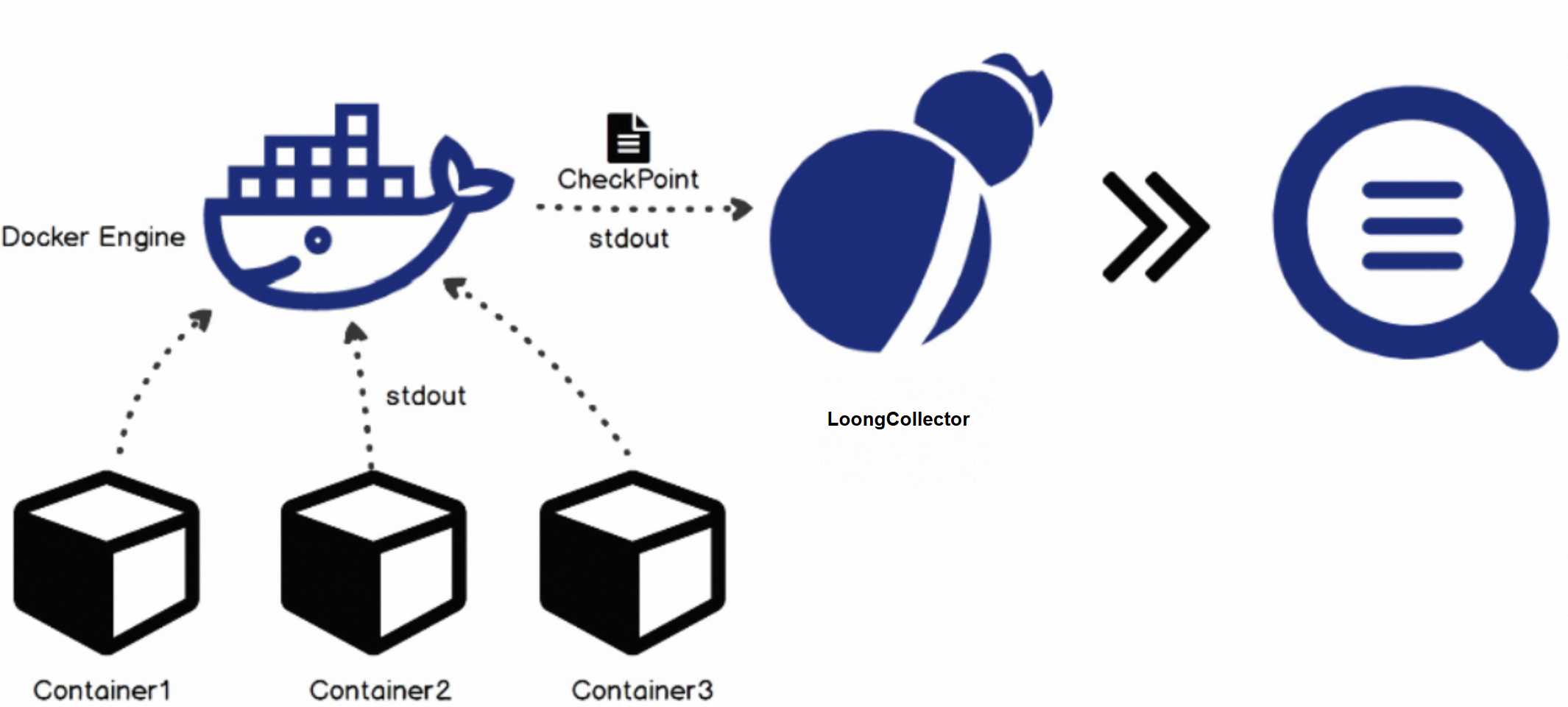
容器文本文件日志采集
K8s容器间文件系统隔离,采集器无法直接访问其他容器的文件。但是,容器内的文件系统都是由宿主机的文件系统挂载形成,通过将宿主机根目录所在的文件系统挂载到Loongcollector容器,就可以访问宿主机上的任意文件,从而间接采集业务容器文件系统的文件。
LoongCollector默认将宿主机根目录所在的文件系统挂载到自身的
/logtail_host目录下,一般来说无须再手动挂载,例如日志文件在当前容器内的路径是/log/app.log,假设在宿主机上映射路径是/var/lib/docker/containers/<container-id>/log/app.log。则LoongCollector实际采集的文件路径为/logtail_host/var/lib/docker/containers/<container-id>/log/app.log。
多行日志识别原理
通过自定义的行首正则表达式对每一行日志进行正则匹配。
匹配成功:将该行作为新日志的起始行,并开始构建一条新日志。
匹配失败:将该行追加到当前日志的末尾。
当再次匹配到满足行首正则表达式的行时,当前日志构建完成,并开始下一条日志的构建。
容器停止时的日志处理
运行时 | 容器销毁延迟风险 | 日志完整性 | 优化建议 |
运行时 | 容器销毁延迟风险 | 日志完整性 | 优化建议 |
Docker | 当容器被停止时,LoongCollector会立刻释放容器文件句柄,容器可正常退出。 | 如果在容器停止前,出现因网络延迟、资源占用多等原因导致的采集延时,可能会丢失容器停止前的部分日志。 | 增加日志发送频率(调小 |
Containerd | 当出现网络延迟、资源占用多等原因导致的采集延时时,可能会导致业务容器不能及时销毁。 | 当容器被停止时,LoongCollector会持续持有容器内文件的句柄(即保持对日志文件的打开状态),直至所有日志文件内容发送完毕。 | 配置 |
容器元信息获取原理
在容器元信息获取方面,LoongCollector 基于标准 CRI API 直接与容器运行时进行交互,实现 K8s 下各类元数据信息获取,从而无侵入地实现采集时的 K8s 元信息 AutoTagging 能力。这种直接与运行时交互的机制,不仅增强了数据获取的实时性,还提高了对于容器状态的管控能力。
Docker:利用 Docker Client 与 Docker Daemon 进行通信,直接获取容器的元信息。通过这种方式,可以实现对容器的深入监控和管理。主要使用到的接口包括:
ContainerList:获取当前运行容器的列表,快速了解当前节点上有哪些容器在运行。
ContainerInspect:提供每个容器的详细信息,包括配置、状态等关键信息。
Events:实时监听容器变化事件,允许动态跟踪容器的生命周期,及时更新相关处理逻辑。
通过 Docker Client 获取容器元信息时,有几项信息尤为重要:
LogPath:这是容器标准输出日志文件在宿主机上的存放路径,方便用户进行日志收集和分析。
GraphDriver.Data:提供容器 rootfs 在节点宿主机上的路径,关键于了解容器文件系统的存储方式,有助于进行故障诊断和性能优化。
Containerd:通过 CRI(Container Runtime Interface),LoongCollector 充分支持在 containerd 和 cri-o 运行时环境下的多种应用场景。无论底层使用的是 runc 还是 Kata Containers,都能够高效地采集和获取容器的元信息。这意味着,无论容器运行在何种环境下,都能保证准确、统一的日志数据采集,帮助用户实时监控和分析日志数据。
CRI 所提供的容器元信息中,仅包含了容器标准输出日志文件在节点宿主机上的路径,而容器的 Rootfs 路径却无法直接获取。为了解决这一问题,采取了以下方案:
文件路径搜索:通过对宿主机的文件系统进行搜索,定位到容器的 Rootfs 路径。这种方法包括遍历宿主机上的文件目录,利用容器的唯一标识符(如容器 ID)进行关联查找,从而实现对容器文件系统的检索和获取。这种动态搜索机制,能够在一定程度上克服路径信息缺失带来的困扰,为后续的日志收集和监控提供支持。
绕过 CRI直接与 containerd 进行交互:选择与 containerd 进行低层次的直接通讯,以获取更全面和准确的容器信息。通过这种方式,LoongCollector能够绕过 CRI 的限制,获得容器的 Rootfs 路径和其他重要元数据。
配置流程总览
登录集群并准备日志源:准备标准输出日志或文本文件日志用于后续采集。
安装Loongcollector采集器:日志服务通过Loongcollector采集并传输日志。
采集配置与解析插件配置 :用于定义采集的规则。
查询与分析日志:查询采集到的日志进行业务状况的分析。
关键流程选型说明
准备日志源
对于标准输出类型的日志,LoongCollector会根据容器元信息自动识别获取文件所在路径。
对于容器文本文件类型的日志,LoongCollector默认将宿主机根目录挂载到自身的
/logtail_host目录下,一般来说无须再手动挂载。如果需要自定义挂载点需满足:
安装采集器
根据适用场景选择部署模式:
部署模式:日志服务支持Daemonset与Sidecar两种模式安装LoongCollector。
Daemonset 部署模式:一次配置,自动在集群的每个Node节点上部署一个 LoongCollector,大多数情况下使用该模式。
当使用Daemonset时,需要根据集群与日志服务的关系选择合适的部署方式。
当使用ACK集群时,ACK中已集成loongcollector-ds组件,只需在ACK控制台选择开启组件使用即完成安装,此方式默认与ACK集群所属阿里云账号绑定,即后续日志会存储在该阿里云账号的日志服务中。具体操作可参考一键自动安装LoongCollector。
当使用ACK集群,但因为组织架构、权限隔离或统一监控等原因,需将该ACK的日志数据采集到另一个独立的阿里云账号的日志服务Project时,需要手动安装LoongCollector组件,并为其配置目标账号的主账号ID或访问凭证(AccessKey)来实.现关联。具体操作可参考手动安装LoongCollector。
当使用自建集群时,需要手动安装LoongCollector组件,为其配置目标账号的主账号ID或访问凭证(AccessKey)来实现关联。具体操作可参考手动安装LoongCollector。
安装LoongCollector是采集日志的前提,您也可以直接参考通过Kubernetes CRD采集集群容器日志(标准输出/文件)进行完整的采集流程操作,其中包含了安装LoongCollector的步骤。
Sidecar部署模式:每个 Pod 中伴随业务容器注入一个 LoongCollector Sidecar容器,部署运维较复杂。当需要Serverless 容器日志采集、单节点 Pod 数据量远超Daemonset采集上限、K8s + 安全容器运行时的日志采集时,使用采集集群文本日志(Sidecar)。
采集规则配置
日志服务提供了如下三种方式来定义采集配置规则:
配置方式 | 特点 | 适用场景 | 注意事项 |
配置方式 | 特点 | 适用场景 | 注意事项 |
| 生产集群优先选择CRD模式,支持CI/CD自动化的场景。 | ||
| 大规模集群需逐个关联配置,因此适合小型集群、临时调试、非生产环境使用。 | ||
极简启动:容器启动时注入变量即可。 | 配置分散,支持的配置内容有限,无法满足日志解析需求。仅适用于对原始日志无解析需求场景。 |
最佳实践
多个集群/环境下日志采集后统一查询分析
比如测试,生产等不同环境集群的日志需要统一进行查询分析,可以有三种方式:
在采集数据时,将数据储存在同一个Logstore,建议通过日志标签富化添加Tag来区分环境。当需要统一查询时,即可在该Logstore中直接进行查询分析。
在采集数据时,采集到不同的Logstore甚至是不同地域的Project中,当需要统一查询分析时,通过创建虚拟资源StoreView来关联多个Logstore进行查询。此方式不额外增加存储,但只能查询不能修改,且不支持设置告警进行监控。使用时可通过tag字段判断日志来自哪一个Logstore。
(推荐)在采集数据时,采集到不同的Logstore甚至是不同地域的Project中,当需要统一查询分析时,通过数据加工将选取的数据复制并存储到指定的Logstore中。此方式可对选取的数据进行解析处理后再进行存储,支持设置告警监控,但该功能需要额外收费。
一个配置如何采集不同来源日志
当前单个采集配置不支持配置多来源,如有需要,通过配置多个采集配置来覆盖不同来源的日志。
精细化采集/多租户隔离
多租户情况下,可以配置不同的采集配置,将数据采集到不同的Project中进行隔离,不同Project之间数据无法直接访问。对不同Project配置不同的访问权限,满足安全隔离的需求。
自动化运维与CI/CD集成
通过CRD方式,将采集配置纳入GitOps/IaC流程,实现批量、自动化、可追溯的日志采集管理。
- 本页导读 (1)
- 功能特点
- 使用限制
- 核心概念
- 日志采集原理
- DaemonSet模式原理
- Sidecar模式原理
- 容器发现原理
- 标准输出采集
- 容器文本文件日志采集
- 多行日志识别原理
- 容器停止时的日志处理
- 容器元信息获取原理
- 配置流程总览
- 关键流程选型说明
- 准备日志源
- 安装采集器
- 采集规则配置
- 最佳实践
- 多个集群/环境下日志采集后统一查询分析
- 一个配置如何采集不同来源日志
- 精细化采集/多租户隔离
- 自动化运维与CI/CD集成