
思源笔记用Python+quicker实现自动添加标题编号
实现原理: 通过 Python 访问笔记的源文件, 将标题前面增加编号+tab 键, 在写回源文件
为防止重复写入, 每次编号前会清理之前编号清除, 清理原理为将标题行用 tab 键分割, 只保留最后一个 tab 后的内容, 因此标题中除了标号后面的 tab 键之外, 不能有其他 tab 键
源代码如下:
#清理标题代码
import json
import pyperclip
class ClearHeader:
def run(self,file_path):
with open(file_path,'r',encoding='utf-8') as f:
result = f.read()
temp_dict = json.loads(result)
for i in range(len(temp_dict['Children'])):
if(temp_dict['Children'][i]["Type"] == "NodeHeading"):
ss = temp_dict['Children'][i]["Children"][0]["Data"]
temp_list = ss.split('\t')
temp_dict['Children'][i]["Children"][0]["Data"] = temp_list[-1]
text_str = json.dumps(temp_dict,sort_keys=False, indent=4, separators=(',', ': '), ensure_ascii=False)
with open(file_path, 'w',encoding='utf-8') as f:
f.write(text_str)
if __name__ == "__main__":
file_path = pyperclip.paste().replace('\"','')
s = ClearHeader()
s.run(file_path)
添加标题代码:
import json
from clear_header import ClearHeader
import pyperclip
file_path = pyperclip.paste().replace('\"','')
s = ClearHeader()
s.run(file_path)
header_index = [0,0,0,0,0]
with open(file_path,'r',encoding='utf-8') as f:
result = f.read()
temp_dict = json.loads(result)
# print(temp_dict['Children'])
for i in range(len(temp_dict['Children'])):
# print(each['Children'],type(each['Children']))
if(temp_dict['Children'][i]["Type"] == "NodeHeading"):
if(temp_dict['Children'][i]["HeadingLevel"]==1):
header_index[1] += 1
header_index[2] = 0
header_index[3] = 0
header_index[4] = 0
temp_header = str(header_index[1]) + '\t'
elif(temp_dict['Children'][i]["HeadingLevel"]==2):
header_index[2] += 1
header_index[3] = 0
header_index[4] = 0
temp_header = str(header_index[1])+'.'+str(header_index[2]) + '\t'
elif(temp_dict['Children'][i]["HeadingLevel"]==3):
header_index[3] += 1
header_index[4] = 0
temp_header = f'{header_index[1]}.{header_index[2]}.{header_index[3]}\t'
elif(temp_dict['Children'][i]["HeadingLevel"]==4):
header_index[4] += 1
temp_header = f'{header_index[1]}.{header_index[2]}.{header_index[3]}.{header_index[4]}\t'
temp_dict['Children'][i]["Children"][0]["Data"] =temp_header + temp_dict['Children'][i]["Children"][0]["Data"]
print(temp_dict['Children'][i]["Children"][0]["Data"],)
text_str = json.dumps(temp_dict,sort_keys=False, indent=4, separators=(',', ': '), ensure_ascii=False)
with open(file_path, 'w',encoding='utf-8') as f:
f.write(text_str)
使用时只需要复制当前笔记文件的绝对路径, 然后执行响应的 Python 文件即可
如果安装了 quicker, 可以更加方便的启动
最终效果为:
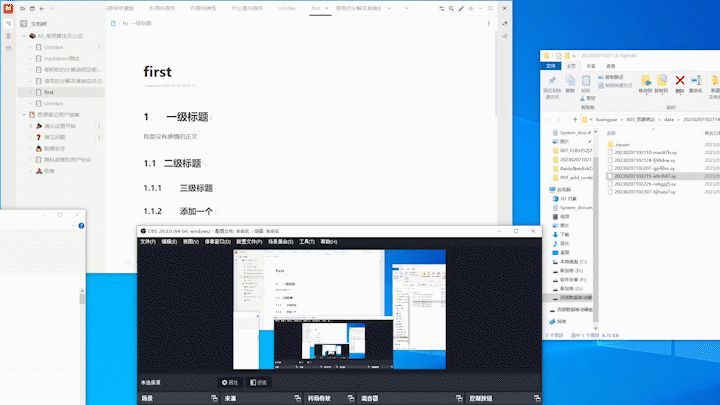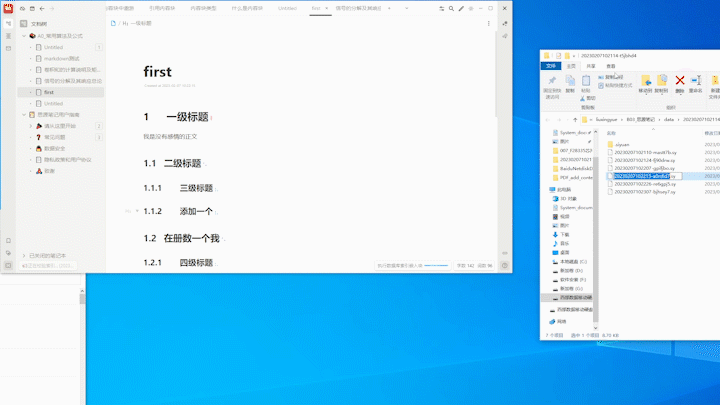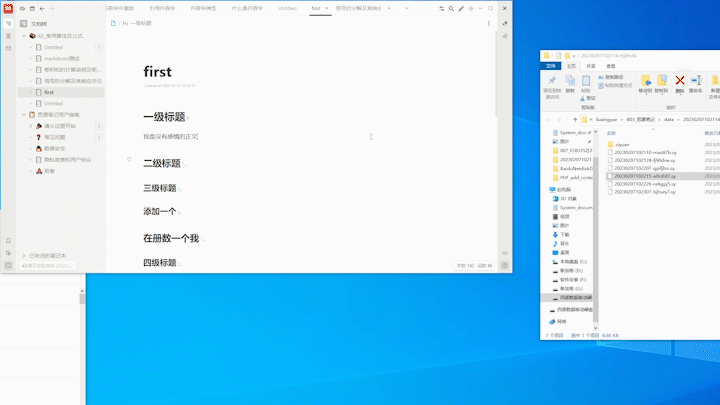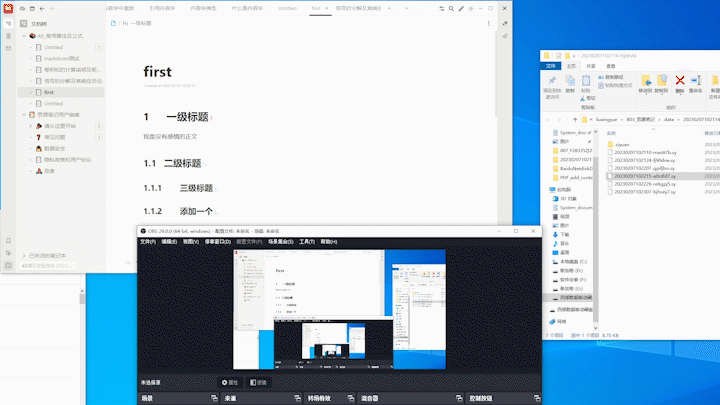
注意, 执行完程序后 F5 刷新, 思源才会更新显示
如果没有 Python 和 quicker , 也可以把 Python 发布成 exe 文件, 复制地址后, 双击运行对应 exe 即可

注意:此程序没有经过长时间测试,可能有bug,使用前源文件做好备份,
Python发布exe文件较大,故未上传,有需要可以发邮件给我liuxingyyue@qq.com


【推荐】还在用 ECharts 开发大屏?试试这款永久免费的开源 BI 工具!
【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· C# 13 中的新增功能实操
· Vue3封装支持Base64导出的电子签名组件
· 万字长文详解Text-to-SQL
· Ollama本地部署大模型总结
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(4)