原码、反码、补码的产生、应用以及优缺点有哪些?
59 个回答

原码、反码、补码的产生、应用以及优缺点有哪些?
我尝试硬生生的把它们串起来哈
数字在自然界中抽象出来的时候,一棵树,两只猪,是没有正数和负数的概念的
计算机保存最原始的数字,也是没有正和负的数字,叫没符号数字
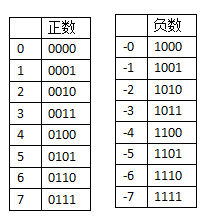
如果我们在内存分配4位(bit)去存放无符号数字,是下面这样子的

后来在生活中为了表示“欠别人钱”这个概念,就从无符号数中,划分出了“正数”和“负数”
正如上帝一挥手,从混沌中划分了“白天”与“黑夜”
为了表示正与负,人们发明了"原码",把生活应该有的正负概念,原原本本的表示出来
把左边第一位腾出位置,存放符号,正用0来表示,负用1来表示
但使用“原码”储存的方式,方便了看的人类,却苦了计算机
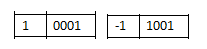
我们希望 (+1)和(-1)相加是0,但计算机只能算出0001+1001=1010 (-2)
这不是我们想要的结果 (╯' - ')╯︵ ┻━┻
另外一个问题,这里有一个(+0)和(-0)
为了解决“正负相加等于0”的问题,在“原码”的基础上,人们发明了“反码”
“反码”表示方式是用来处理负数的,符号位置不变,其余位置相反

当“原码”变成“反码”时,完美的解决了“正负相加等于0”的问题
过去的(+1)和(-1)相加,变成了0001+1101=1111,刚好反码表示方式中,1111象征-0
人们总是进益求精,历史遗留下来的问题—— 有两个零存在,+0 和 -0
我们希望只有一个0,所以发明了"补码",同样是针对"负数"做处理的
"补码"的意思是,从原来"反码"的基础上,补充一个新的代码,(+1)
我们的目标是,没有蛀牙(-0)


有得必有失,在补一位1的时候,要丢掉最高位
我们要处理"反码"中的"-0",当1111再补上一个1之后,变成了10000,丢掉最高位就是0000,刚好和左边正数的0,完美融合掉了
这样就解决了+0和-0同时存在的问题
另外"正负数相加等于0"的问题,同样得到满足
举例,3和(-3)相加,0011 + 1101 =10000,丢掉最高位,就是0000(0)
同样有失必有得,我们失去了(-0) , 收获了(-8)
以上就是"补码"的存在方式
结论:保存正负数,不断改进方案后,选择了最好的"补码"方案
如果对您启发,欢迎关注我,我是 @知乎-李俊达
计算机知识的需要养成每天思考,每天学习的习惯,如果你有三天打鱼两天晒网的困惑,欢迎关注我一个关于毫不费力轻松培养良好习惯的知乎答案

一、序言
第一版答案写于2016年8月,当时我正试图理解补码规则的逻辑,并用结果写了一篇回答发在知乎和公众号上,因为收到的回复很乐观,让我一度认为已经把握问题的全貌。事实上答案在符号位的论述上存在谬误,多亏知友在回复中指出,为此我进行了更深入的思考,重新编辑此答案,希望能更接近问题的本原。
二、重温运算规则
首先我想把整套关于原码反码补码的运算规则准确清晰地写一遍,方便急需应用的知友参考,也希望大家首先能记住这套规定,再开始进一步的探讨。
所谓原码就是机器数,是加了一位符号位的二进制数,正数符号位为0,负数符号位为1,计算机中存储、处理、运算的数据通常是8位、16位、32位或64位的,这里以最简单的8位为例讲解。注意符号位是包含在8位中的其中1位,故可直观读出的数只有7位(只有后7位数可以按权展开)。有心人可能注意到原码是有缺陷的,它只能表示255种状态,因为00000000(+0)和10000000(-0)其实是一个数,因此原码的表示范围成了-127到+127,这个问题需要神奇的补码来解决,因为在补码中10000000被用来表示-128。
所谓反码,英语里又叫ones' complement(对1求补),这里的1,本质上是一个有限位计数系统里所能表示出的最大值,在8位二进制里就是11111111,在1位十进制里就是9,在3位十六进制里就是FFF(再大就要进位了)。求反又被称为对一求补,用最大数减去一个数就能得到它的反,很容易看出在二进制里11111111减去任何数结果都是把这个数按位取反,0变1,1变零,所以才称之为反码。用原码求反码的方法是,正数不变,负数保留符号位1不变,剩下位按位取反。
所谓补码,英语里又叫two's complement(对2求补),这个2指的是计数系统的容量(模),就是计数系统所能表示的状态数。对1位二进制数来说只有0和1两种状态,所以模是10也就是十进制的2,对7位二进制数来说就是10000000,这个模是不可能取到的,因为位数多一位。用模减去一个数(无符号部分)就能得到这个数的补,比如10000000-1010010=0101110,事实上因为10000000=1111111+1,稍加改变就成了(1111111-1010010)+1,所以又可以表述为先求反再加1。总结求补码的方法就是正数依旧不变,负数保留符号位不变,先求反码再加上1。
记住了怎么求补码,接下来讲讲运算。通过原码的符号位和数值,我们能迅速指出它代表的数,判断其正负并进行四则运算,相比而言反码和补码对于人则显得过于晦涩。如果说原码是给人看的数字语言,那么补码就是计算机的数字语言。计算机不需要知道什么是正负、大小,这些判断对它而言过于复杂。事实上它存储、处理、传输的数都只有补码一种形式,人所做的加减乘除,在计算机里只通过相加和移位就能解决,这都来自于补码系统的内在自洽和巧夺天工的神奇魔力,也是后文要阐述的重点。
对加法和减法,按上文的方法求得补码之后,直接相加就可以了,但相加的时候符号位一定要一起参与运算,有时候,两符号位相加或者接受来自低位的进位会发生溢出,就扔掉溢出的一位(稍后会解释为什么),由新的符号位决定结果的正负,如果是0表示正数,结果就是原码,如果是1表示负数,结果还要再求补数得到原码。
至此我介绍了原码反码补码的规定,以及如何求补码并进行加减法(乘除暂不涉及,事实上懂了加减法的奥秘,乘除很容易理解),对于一个工程人才来说,上面的内容已经足够应付所有具体问题。剩下的则是一些“无用”的思考,关于为何这套法则能够化减为加,以及人为规定的符号位在运算中为何总是能精确地指示结果的符号。
三、无用之用
数字是用来记录现实世界数量属性的语言。
而任何计数系统都必须有两个参数:容量和精度。
模是衡量计数系统容量的参数。模代表了计数系统所能表示和存储的状态数。
任何有限的计数系统都有一个确定的模。如时钟的模是12(即只有一个位的十二进制系统,若再加一个大钟,使小钟转一周大钟加一刻度,就是有两个位的十二进制系统),再比如8位计算机的模是2^8=256D(每一位也可以单独看做一个模为2的计数系统)。
问题一:化减为加
对同一计数系统中的数量可以定义运算如加减,但运算结果超出预设位数时,就要发生溢出,这个溢出其实就是模,是时钟的一整圈(因此丢掉它没有影响),如果进位没有被另一个计数系统接受,结果看似“失真”,本质上是进入了“第二次循环”。
以时钟系统为例:8+7=15D=13(十二进制)>10(十二进制),进位1溢出丢失(除非用另一个时钟接收这个进位),在表盘上(即一位十二进制计数系统中)呈现为3,而8-5=8+(-5)=3也得到了相同结果。这就说明在有限容量的计数系统中,+7和-5是完全相同的,而它们正是关于模12的一对补数。
因此我们在有限的计数系统做了这种定义:正数补数即为本身,负数A【补】=模-绝对值(A)。一个数加上另一个数(可以是正数也可以是负数),结果等于加上这个数的补数,若有进位则舍弃进位。这么做的重大意义在于极大地方便了计算机进行数据处理,要知道对人而言减法并非难事,但用门电路实现就复杂得多了,减之前还要判断大小考虑次序。
问题二:符号位参与运算
在8位计算机中,一个字节可以表示256种状态,把字节看做一个钟的话,刻度可以随便标,不如取0点钟为-128,正对的6点钟为0,即存储范围是从-128到127,用二进制补码表示是10000000~01111111(10000000用来表示-128似乎是人为定义的,因为原码无法表示-128,按正常程序更无法求得其补码)。

符号位是我认为理解补码的关键所在,也是关于补码最神奇的地方。人类“生硬”地添加了符号位,把256种状态剪成正负两半,还“生硬”地规定-128的补码为10000000,但用补码运算的时候,一切就像“水往低处流”般正确和谐自然:符号位参与运算,接受来自低位的进位,永远能忠实地指示结果的正负。
我举个例子,你们感受一下:
所谓的“负数加负数会变成正数,正数加正数会变成负数”,本质还是在于,计数系统是无法表示超出其取值范围的计算结果的。
120D+120D=01111000B+01111000B=11110000B,符号位的1来自低位进位,指示了结果是负数,所以需要求补得10010000B也就是-16D,放在钟面上就是从120顺时针旋转120格到240的位置,只不过系统最大只取到127,240的位置就是-16的位置,而且-16和240正是关于模256的一对补数。-120D-120D=16D也是一样的道理。在有限的计数系统内,由于位数的限制,发生溢出的情况下无法得到计算真实值,得到的是真实值关于模的补数。

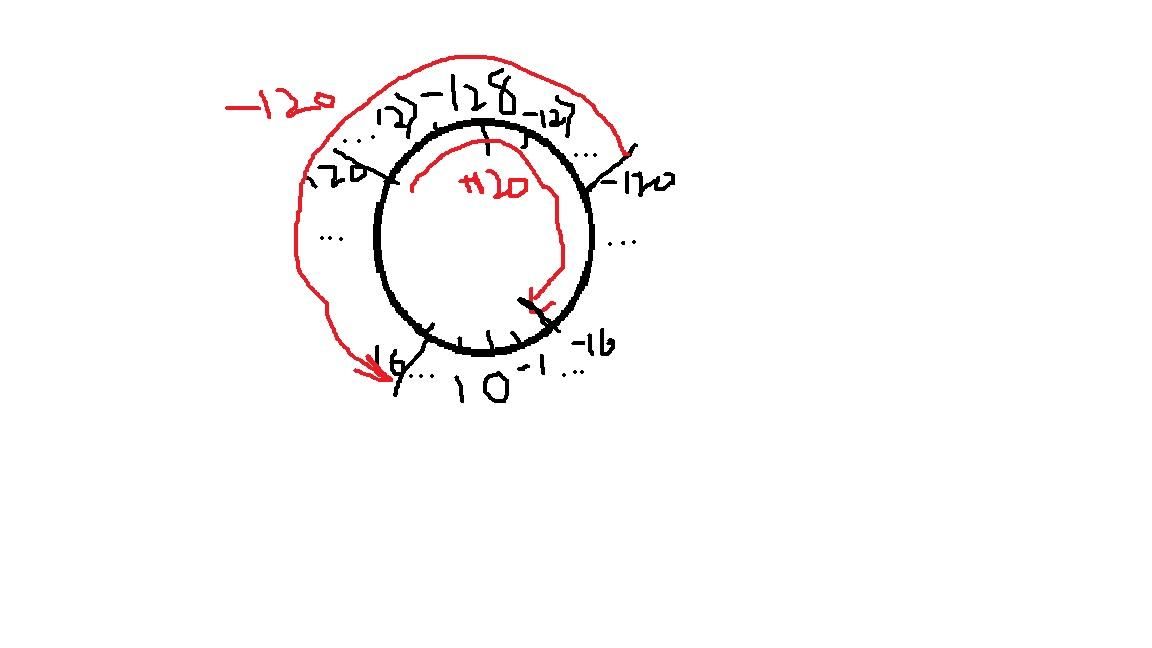
看到这里是不是有那么点味道呢,我给你们总结一下:加法都是从低位往高位做的,如果两个数(补码),后七位相加产生了进位,说明
又溢出了一次,每当溢出一次(就是越过了-128这个正负分界点),符号就要反一下,0变1,1变0。符号是1的,说明大得越界了,需要再求个补,用取值范围内的负数表示结果;符号是0的,说明小得越界了,但由于正数的补数就是本身,就不必再求补了。
四、后记
从八月底的初稿到这篇文章,中间经历了差不多四个月的时间,我对于补码问题的认识也经历了困惑到清晰到困惑到再清晰这一过程,其中修改超过十次,思考所花的时间更是不计其数。从参加考试的角度看,我熟记的运算规则早已足够我应付所有题目,但我仍然不愿意半途而废,原因有二:
大一学习线性代数时,曾经挂过科,因为对于定理和公式背后的含义一无所知,而老师也不加讲解,只一味让我们死记做题。虽然很多同学都适应这种所谓的“工科数学学习”,然而这对我而言简直如同梦魇,没有理解内化如何能称得上学习,不过是应付考试然后忘的精光罢了。我很幸运的是,在准备补考时读到了网上广为流传的孟岩老师的文章《理解矩阵》,我记得那是一个冬天的晚上,读完文章后我很兴奋,一直到半夜都睡不着,这是我第一次体会到数学体系的和谐自洽以及数学的深刻性在工程中的巨大威力,从那以后我才逐渐找到了学习数学的乐趣。
《理解矩阵》中有一段话至今我还记得,现摘抄如下:
自从1930年代法国布尔巴基学派兴起以来,数学的公理化、系统性描述已经获得巨大的成功,这使得我们接受的数学教育在严谨性上大大提高。然而数学公理化的一个备受争议的副作用,就是一般数学教育中直觉性的丧失。数学家们似乎认为直觉性与抽象性是矛盾的,因此毫不犹豫地牺牲掉前者。然而包括我本人在内的很多人都对此表示怀疑,我们不认为直觉性与抽象性一定相互矛盾,特别是在数学教育中和数学教材中,帮助学生建立直觉,有助于它们理解那些抽象的概念,进而理解数学的本质。反之,如果一味注重形式上的严格性,学生就好像被迫进行钻火圈表演的小白鼠一样,变成枯燥的规则的奴隶。
“枯燥的规则的奴隶”又何止是在数学教学中出现的呢?如果你在大学工科学习过,你会发现这些人简直遍地都是,拿我在的浙大为例,有的是学生对课程并不理解,单靠考前突击刷题就拿到90分以上的成绩。
正是在这样的情形下,我决定尽我所能重新思考学到的每一个重要知识,并将其中一部分写成文章,一来有助于对思维的梳理,二来也是便于自己将来的回顾,倘若拙作还能对他人也有所帮助,从而使我给世界留下一些微不足道的影响,那真是幸甚了。