
福利 - 不过百行代码的爬虫爬取美女图

序言
闲的无聊,看到一个段子网站的美女福利还不错,迫于福利加载太慢看的不过瘾,就想用Nodejs写个简单爬虫全部爬下来看多好..... 此处省略5000字.....
准备
要爬,首先得要有目标,我呢,就把目标锁定到了 某哈,然后呢就是用浏览器来分析分析其中的规律
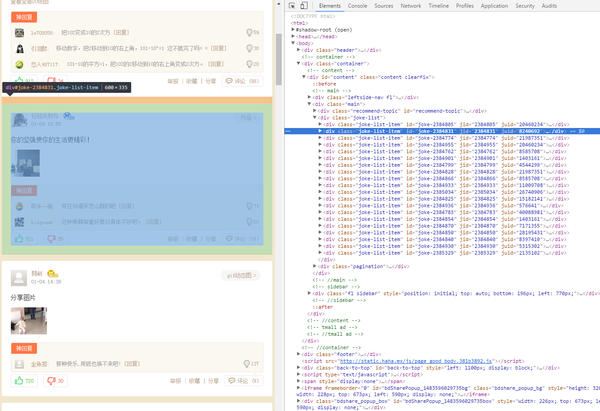

从中可以看到每一条段子都是一个 .joke-list-item, 当点击下一页的时候 url中地址的最后一位数就表示分页的页码。有些图片是缩略图,我们把缩略图和正常图的地址进行了比较,发现他们的地址格式是一样的,缩略图在small文件夹下,大图在big文件夹下。分析完了我们就可以写代码了。
开始
这个简单爬虫分两个部分,1、获取图片地址。2、进行下载。因为下载是一个耗时的操作,所以两个部分分开了,这样也有利于后期改动。
导入必要的模块,使用cheerio 是第三方模块,可以使用 npm install cheerio 进行安装
var http = require('http'); // http 网路
var cheerio = require('cheerio'); // html 解析
var fs = require("fs"); // 流
var queryHref = "http://www.haha.mx/topic/1/new/"; // 设置被查询的目标网址
var querySearch = 1; // 设置分页位置
var urls = []; // 所有待下载的图片地址
这个是解析图片地址方法
/**
* 根据url和参数获取分页内容
* @param {String}: url
* @param {int}: serach
*/
function getHtml(href, serach) {
var pageData = "";
var req = http.get(href + serach, function(res) {
res.setEncoding('utf8');
res.on('data', function(chunk) {
pageData += chunk;
});
res.on('end', function() {
$ = cheerio.load(pageData);
var html = $(".joke-list-item .joke-main-content a img");
for(var i = 0; i < html.length; i++) {
var src = html[i].attribs.src;
// 筛选部分广告,不是真的段子
if (src.indexOf("http://image.haha.mx") > -1) {
urls.push(html[i].attribs.src)
}
}
});
});
}
这个是下载图片的方法
/**
* 下载图片
* @param {String} imgurl:图片地址
*/
function downImg(imgurl) {
var narr = imgurl.replace("http://image.haha.mx/", "").split("/")
http.get(imgurl.replace("/small/", "/big/"), function(res) {
var imgData = "";
//一定要设置response的编码为binary否则会下载下来的图片打不开
res.setEncoding("binary");
res.on("data", function(chunk) {
imgData += chunk;
});
res.on("end", function() {
var savePath = "./upload/topic1/" + narr[0] + narr[1] + narr[2] + "_" + narr[4];
// 保存图片
fs.writeFile(savePath, imgData, "binary", function(err) {
if(err) {
console.log(err);
}
});
});
});
}
好,到这里核心的东西就写完了,然后就是组装一下,让他运行起来
附一个完整代码:
var http = require('http'); // http 网路
var cheerio = require('cheerio'); // html 解析
var fs = require("fs"); // 流
var queryHref = "http://www.haha.mx/topic/1/new/"; // 设置被查询的目标网址
var querySearch = 1; // 设置分页位置
var urls = [];
var sumConut = 0;
var reptCount = 0; // 重复的
var downCount = 0; // 实际下载的
/**
* 根据url和参数获取分页内容
* @param {String}: url
* @param {int}: serach
*/
function getHtml(href, serach) {
console.log("正在获取第 "+serach + " 页的图片");
var pageData = "";
var req = http.get(href + serach, function(res) {
res.setEncoding('utf8');
res.on('data', function(chunk) {
pageData += chunk;
});
res.on('end', function() {
$ = cheerio.load(pageData);
var html = $(".joke-list-item .joke-main-content a img");
for(var i = 0; i < html.length; i++) {
var src = html[i].attribs.src;
// 筛选部分广告,不是真的段子
if (src.indexOf("http://image.haha.mx") > -1) {
urls.push(html[i].attribs.src)
}
}
// 递归调用
if (serach < pagemax) {
getHtml(href, ++serach);
} else {
console.log("图片链接获取完毕!");
sumConut = urls.length;
console.log("链接总数量:" + urls.length);
console.log("开始下载......");
downImg(urls.shift());
}
});
});
}
/**
* 下载图片
* @param {String} imgurl:图片地址
*/
function downImg(imgurl) {
var narr = imgurl.replace("http://image.haha.mx/", "").split("/")
// 做一步优化,如果存在文件,则不下载
var filename = "./upload/topic1/" + narr[0] + narr[1] + narr[2] + "_" + narr[4];
fs.exists(filename, function(b){
if (!b) {
// 文件不存则进行 下载
http.get(imgurl.replace("/small/", "/big/"), function(res) {
var imgData = "";
//一定要设置response的编码为binary否则会下载下来的图片打不开
res.setEncoding("binary");
res.on("data", function(chunk) {
imgData += chunk;
});
res.on("end", function() {
var savePath = "./upload/topic1/" + narr[0] + narr[1] + narr[2] + "_" + narr[4];
fs.writeFile(savePath, imgData, "binary", function(err) {
if(err) {
console.log(err);
} else {
console.log(narr[0] + narr[1] + narr[2] + "_" + narr[4]);
if (urls.length > 0) {
downImg(urls.shift());
downCount++;
console.log("剩余图片数量....");
}
}
});
});
});
} else {
// 统计重复的图片
console.log("该图片已经存在重复.");
reptCount++;
if (urls.length > 0) {
downImg(urls.shift());
}
}
});
if (urls.length <= 0) {
console.log("下载完毕");
console.log("重复图片:" + reptCount);
console.log("实际下载:" + downCount);
}
}
var pagemax = 30; // 获取到多少页的内容
var startindex = 1; // 从多少页开始获取
function start(){
console.log("开始获取图片连接");
getHtml(queryHref, startindex);
}
start();
因为nodejs是异步的,所以在 start 方法中的for之后调用下载是不行,这个时候显示的 urls 中是没有数据的。
所以就是在 getHtml 中 等所有的连接分析完毕之后在调用 downImg,downImg下载完成之后在进行下一个下载。
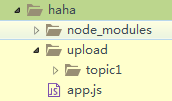
项目目录很简单,如图:
然后我们切换到项目目录,执行 node app , 然后就静静的等待把,每次下载完一个会有对应的文件名打印出来的。
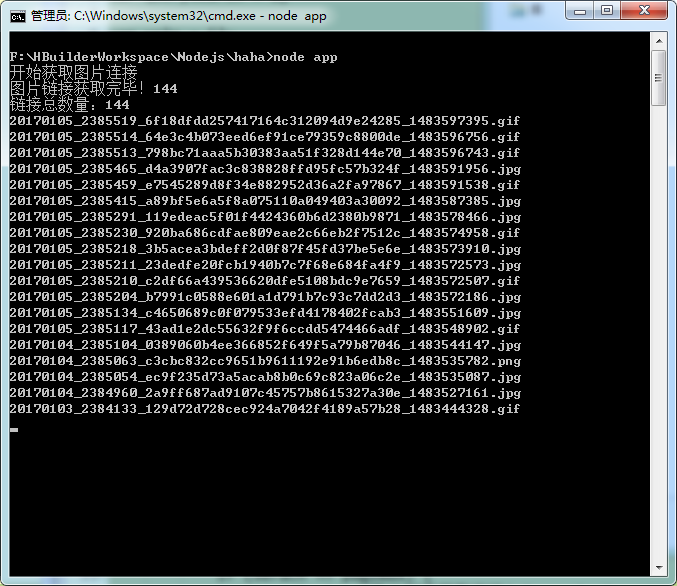

最后会出现 下载完毕!,之后就....... 你懂得......
这个是一个很简单的,当然后续你可以加上数据库,数据更新之类的.....
放几张我爬到的图
。
。
。
。
。
。
。
。
。
注意前方高能
注意前方高能
注意前方高能
。
。
。
。
。
。
。
。
。
。
。
。



嘘... 不要告诉别人....
17.1.6
更一次,评论区有人说我这个有点歪风邪气,这个小程序是一个初级入门的代码,但是不仅仅只限于去爬去美女图片,你也可以去爬一些你感兴趣的东西,有些说我在误导小朋友,其实每一门语言都是博大精深的,其中的细节非常之多,而新手可以运行起来是应为很多东西都是用的默认值,如果要处理好每一个细节,还是需要非常完整的只是体系的。
17.1.7
在更一次,第一次这么多赞,谢谢各位,看到评论去有很多朋友指出了一些问题,再此非常感谢,尤其是并发这一块,这个并发确实处理的不恰当,今天改了一下,控制了一下并发,但是代码略超100行,不幸的是好像我的ip被评论中的一个小伙伴说中了,貌似被封了...封了...封了...封了...了...了...了.....
