
《知识图谱》专题论文解读(6篇顶会/顶刊论文)

TKDE


■ 链接 | https://www.paperweekly.site/papers/2194
■ 解读 | 花云程,东南大学博士,研究方向为自然语言处理、深度学习、问答系统
动机
对于基于知识图谱的事实性问答(KBQA),采用基于语法分析的方法,大致分为两个阶段:其一为问题理解,即将问题转换为 SPARQL 类型的结构化查询;其二为查询评分,即对产生的结构化查询进行置信度评分。
在问答系统中,重点是解决第一阶段中的歧义性问题,即解决:第一,短语链接问题,即如何将自然语言问句中的短语链接到正确的实体/类/关系/属性上;第二,复合问题,即一个自然语言问题可能转换为多个知识图谱三元组,而这多个三元组如何组合,才正确表达了问题的意图,并由此得到正确答案。
因此,为了解决第一阶段的两个问题,本文提出基于图匹配的方法,将解决歧义问题与查询评分这两个阶段融合在一起,即当得到自然语言问题的一个正确匹配的查询子图时,歧义问题也已经同时解决了。
本文为了将自然语言转换为查询图,提出了关系优先(relation-first)和点优先(node-first)的方法。前者从自然语言问句中,尽量抽取对应的关系,并从句法树中抽取实体来构成查询图;后者从问句中尽量抽取对应的实体,再对实体之间的边进行填充,来构成查询图。该方法不需要事先人工设立模板,且对复杂问句分析非常有效。
贡献
文章的贡献有:
1. 不同于已有的基于模板的工作,本文工作不需要预先设置模板;
2. 不同于已有的基于语义分析的工作,本文工作的将歧义性问题与查询评分问题融合成一个问题来解决;
3. 本文工作对于解决复杂问题非常有效,且对于句法依存树的使用具有容错率。
方法
本文的工作主旨,是建立一个与自然语言问句意图充分匹配的查询图 Qs,这个查询图中可以存在具有歧义性的实体(以节点表示)或关系(以边表示)。当这个查询图被确定下来时,对应的结构化查询也被唯一确定。
为了建立结构化查询,本文首先从问句中形成以自然语言成分组成的查询图 Qs,再通过图 Qs 与知识图谱 G 的同构匹配,来得到结构化查询。本文的工作主要分为线下和线上部分,其中线上部分又分为关系优先(relation-first)和点优先(node-first)的方法。
1. 线下部分的工作
线下工作,主要是建立两个字典,分别用于实体-实体指称和关系-关系指称。
2. 线上部分的工作——关系优先框架(relation-first framework)
首先使用 Stanford Parser 将自然问句N转换为句法依存树 Y。由于在线下部分已经建立了关系指称词典,即每一个词都可能被不同的关系指称所包含,所以在关系优先框架中,对于 Y 中每一个词(节点)wi,先找到所有包含 wi 的关系指称,然后使用深度优先搜索算法来遍历 Y 中以 wi 为根的子树,并判断这个子树是否与当前关系指称一一匹配。
如果一个关系指称中所有的字都在子树中出现,那么认为找到一个匹配的句法依存子树 y,这个关系指称也是符合自然问句 N 的。
当得到关系指称之后,就需要找到与这个关系指称相联系的主语和宾语节点。本文根据统计分析,基于句法树中边的词性,而统计出属于“subject-like”的边,与“object-like”的边。
分析关系指称与句法依存树,若在依存子树 y 中有点 w 是可以被匹配为类/实体,则认为这个w是关系指称的一个主语;否则,观察 w 与它的子节点中,是否被 subject-like 的边相连,若是的话,这个子节点就是这个关系指称的主语。
同理,若 w 与子节点被 object-like 的边相连,那么关系指称的宾语就是这个子节点。如果经过这种规则处理,找不到对应的主语/宾语,那么就需要应用一些高阶规则。
如下图 1 所示,即一个寻找与关系指称相关的主/宾语节点的示例。


如图 1,已知的关系指称为“budget of”与“direct by”,由于“file”是匹配于实体或类,且“of”与子节点“film”之间以 object-like 的边 pobj 相连,所以“film”是关系指称“budget of”的宾语。
此外,虽然“is”与“budget”由subject-like的边相连,但是“is”并不是一个可以匹配到实体/类的节点,所以“is”不是“budget of”的主语。根据前面所述,与“budget of”最相近的 wh- 词是“what”,那么它就是“budget of”的主语。
以上的工作,是通过自然语言问句与句法树的分析,得到了查询图 Q^{s} ,后续需要再通过图 Q^{s}与知识图谱 G 的同构匹配,来得到结构化查询。
Q^{s}中每一条边都有匹配的候选谓词,而Q^{s}中每一个节点都有匹配的候选实体或者类,且根据关系指称词典和实体指称词典,均有一个置信度得分。当Q^{s}与知识图谱 G 进行匹配时,可以找到若干匹配的子图,从中找到分数最大的 top-k 子图,就是找到对应的结构化查询。再执行这个查询,就可以得到问题对应的答案。
3. 线上部分的工作——节点优先框架(node-first framework)
节点优先框架,是从自然语言问句中找到节点,再对填充节点之间的边。当填充边时,肯定会出现同一对节点之间以不同路径相连的问题,所以通过识别节点、再填充边的做法,形成的图为超语义查询图Q^{u},而Q^{s}是其一个子图。
首先用已有的方法识别出所有的实体指称,并且将所有 wh- 词和不能匹配到任何实体的名词作为通配符。比如对于例句“What is thebudget of the film directed by Paul Anderson and starred by a Chinese actor?”可以识别出“what”、“film”、“Paul Anderson”、“Chinese”、“actor”。
其次进行结构的建立。利用句法依存树,当两个节点之间没有其余节点存在,那么这两个节点之间即认为是有边或路径相连,即为一个关系指称,且路径上所有边的label组合成为这个关系指称。
如下图 2 所示,点“film”与点“Paul Anderson”、“actor”之间都没有其余节点存在,所以“film”与“Paul Anderson”存在关系,关系指称为“directed by”;“film”与“actor”存在关系,关系指称为“directedstarred by”,由此得到了节点间的关系指称。
当两个节点之间的指称没有 label 时,如图 2 的“Chinese”和“actor”,那么若两个节点都为实体/类,那么在知识图谱中将这两个节点间的关系填入;若其中一个节点为通配符,则在知识图谱中定位另外一个节点,取与其连接频数最高的那些谓词作为候选关系填入。


经过关系填充,可以得到 Q^{u} ,而Q^{u}中将包含所有节点,但以不同边连接所有节点的子图以 S_{i} 表示。在将S_{i}与结构化查询图进行匹配时,采用基于动态规划的自顶向下的方法来逐步扩展。
即首先找到最可能匹配的部分子图 Q,再将与 Q 中节点相连的边逐一加入,并评估是否可以与知识图谱G中的子图匹配,若可以的话,则继续加入边到 Q,直到 Q 是Q^{u}的包含了Q^{u}所有节点的子图,那么就视为找到了一个语义查询图;若加入了一条边后,后续无法产生匹配,则需要回溯,把这条边从 Q 中删去,重新加一条新边,再进行迭代。
实验
实验使用了 QALD-6 数据集和 WebQuestions 数据集。QALD 中复杂问题较多,相比之下,WebQuestions 中的简单问题(一个问题可以由一个三元组表示)居多。
如图 3 所示的表格,在 QALD-6 的比赛中,NFF(节点优先框架)取得了第二名的成绩,而第一名的 CANaLI 需要用户手动输入实体和谓词,大大减少了系统难度,而 NFF/RFF 不需要这样的人工操作。
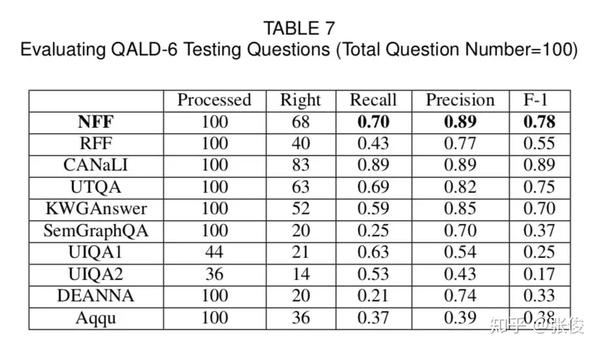

从图 4 所示的表格可以见到,在 WebQuestions 的测试中,NFF 排在第三位,这是由于关系指称词典的覆盖率在 WebQuestions 较低导致。而且,本文系统更加由于复杂问题的处理,所以将 Aqqu 放到 QALD 中,其效果降低了很多,远远不及本文系统。


关于错误回答问题的分析,其一是由于词典中的未登录实体/类/关系,导致匹配错误;其二是对于聚集型问题,本文的方法无法回答。
总结
这篇文章主要提出了一种基于图匹配的方法,来进行自然语言问题的回答。与之前的工作不同的是,在本文的工作中,实体识别、关系识别的歧义性问题是在查询评分的阶段中完成的,而之前的工作是将这两个阶段分开进行。
由于是利用结构化查询图来进行答案检索以及解决歧义,这是个高效的方法。所以,基于图匹配的方法,不仅可以提高系统准确性(尤其是对于复杂问题),而减少了整个系统的响应时间。
此外,这些工作都可以利用文本来进行工程化地实现,并不涉及复杂的神经网络模型,在应用或项目中,容易实现。
IJCAI 2017


■ 链接 | https://www.paperweekly.site/papers/2192
■ 解读 | 李丞,东南大学硕士,研究方向为知识图谱构建及更新
动机
随着知识图谱技术的快速发展,知识图谱正在越来越多的应用中扮演重要的角色。但是现有的知识图谱存在一个很明显的缺陷:图谱中的数据的实时性很差。绝大多数知识图谱从构建完成开始,其中的数据便不再更新。即使有更新,更新的周期也非常长。每一次的更新都是一次费时费力的、类似于重新构建知识图谱的过程。
这样的更新机制一方面需要消耗大量网络带宽和计算资源,另一方面由于每次更新所消耗的代价太大,这就限制了更新的频率,使得知识图谱中数据的实时性非常差。由于缺乏一个实施的更新机制,图谱中这些没有同步更新的数据中存在大量的错误,这使得这些数据无法被利用。这种数据的滞后性给知识图谱的应用带来了很大的局限性。
贡献
1. 本文提出一个实时更新知识图谱数据的方法框架,可以以较高的准确率预测出哪些实体需要被更新,从而以较低的代价和较高的频率对知识图谱进行更新,从而实现了知识图谱的实时、动态更新;
2. 本文将其提出的知识图谱更新框架部署在 cn-dbpedia 上,用于对 cn-dbpedia 的实时更新,更新频率设置为每天更新一次,实践结果表明,更新的效果非常好。
方法


本文所提出的知识图谱更新框架主要分为 4 个步骤:
1. 从互联网上抽取、识别出最近一段时间内热门的实体(以下简称热词)。
热词的抽取来源包括:热门新闻的标题、搜索引擎的热门搜索以及门户网站的热门话题。从这些来源抽取出热门的短语或句子,利用命名实体识别(NER)技术抽取出其中的实体。
由于现有的 NER 技术的召回率都小于 90%,因此为了提高热词抽取的召回率,可以采用一种极端的方法:利用分词技术直接对这些句子和短语进行分词,然后穷举分词后得到的所有实体。如果百科页面中有该实体相关的页面,则该实体便抽取成功。
2. 根据第一步中抽取出的热词,对知识库做更新。
更新的原则是如果知识库中已经存在该实体,就到百科网站中对该实体做知识库实时更新,如果知识库中不存在该实体,就将该实体及其相关的百科信息添加到知识库中。
3. 从前两步被更新的实体的百科页面中的超链接中扩展得到和这些实体语义相关的更多实体,作为候选的待更新实体。
因为某一时间段的热词数量都是有限的,因此通过前两步抽取出的热词数量很少,为了更新更多的实体,需要对热词进行扩展抽取。扩展抽取的方法就是从已经抽取出来的热词的百科页面中的超链接中获取更多的实体。
这一抽取方法是基于这样的原理:如果一个实体在某一时间段内属于热词,它的属性值有可能会被经常更新,那么和它语义相关的实体的属性也很有可能需要被更新。而实体百科页面中的链接正是表达了这样一种语义相关的关系。
4. 对第 3 步得到的候选的待更新实体进行优先级排序,按优先级从高到底,依次对候选队列中的实体到知识库进行更新。
本论文所提出的知识图谱更新框架追求一种实时性,即它对知识库更新的频率的要求是很高的。由于更新的频率非常高,再加上百科网站也存在一定的反爬取策略,因此每次能更新的实体数量是有上限的。
本论文假定每天所挑选出的待更新的实体数量为 K。虽然并不能保证这 K 个实体最终都会有数据被更新,但是要想办法使得最后所挑选出的 K 个待更新实体中,有尽可能多的实体最终得到了更新,而尽可能减少挑选出那些最后不需要被更新的实体,减少无用功。因此所有待更新的实体中,只能挑出部分优先级高的进行更新。
本论文所提出的更新策略为:第 1 步中直接抽取出的热词具有最高的优先级,优先进行更新。对于后面扩展抽取出的相关实体,按照优先级由高到低依次进行更新,直至更新总数达到 K 或者待更新实体队列为空为止。本文提出的优先级刻画模型为:
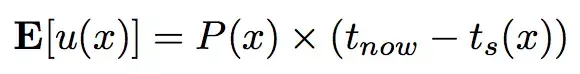

其中 x 为实体,E[u(x)] 是实体 x 的优先级,P(x) 是实体 x 的预测更新频率,该值由本论文设计并训练的回归模型预测得出,ts (x) 是知识图谱中 x 最后一次被更新的时间。如果实体 x 不在知识图谱中,ts (x) 定义为负无穷。由此可以看出,如果候选实体更新队列中的有新的实体(现有知识图谱中没有的实体),那么这些新的实体的更新优先级会很高。
预测 P(x) 值得回归模型通过监督学习的方式训练得到。本论文为每个实体设计了 8 个特征,包括实体在百科中存在的时长、总计被更新次数、用户访问次数、实体页面中所有超链接总数、实体百科页面长度等这些可以反应实体热度的特征。
通过这些特征刻画实体的热度,然后通过监督学习的方式训练生成回归模型并用于预测实体的 P(x) 值。P(x) 值反映的是实体的被更新频率,该值越大,代表实体的热度越高,那么它被更新的优先级也更高。
实验
本文实验采用的数据集是 cn-dbpedia,将本文所提出的更新框架部署在 cn-dbpedia上,并将更新频率设置为每天更新一次。更新效果如下表所示:
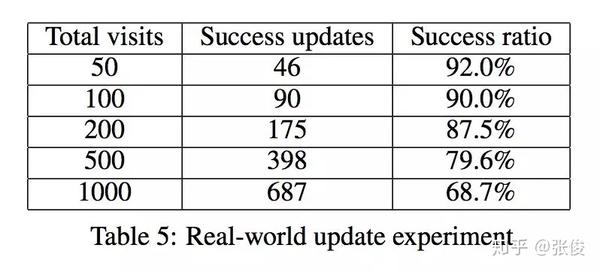

一次成功的更新是指检查实体对应的百科页面中的相关信息,如果该实体的属性发生了改变、需要被更新,那么这次检查是成功的。实验结果表明,该框架在 cn-dbpedia 上更新的成功率较高,能够有效地对知识图谱进行动态的更新。
ICML 2017


■ 链接 | https://www.paperweekly.site/papers/2191
■ 源码 | https://github.com/rstriv/Know-Evolve
■ 解读 | 王旦龙,浙江大学硕士,研究方向为自然语言处理
对于事件数据,需要动态更新的知识图谱来保存知识图谱中关系的时许信息。本文提出了 Know-Evolve 这种基于神经网络的动态知识图谱来学习实体在不同时刻的表示。
在动态知识图谱中,事件由四元组表示,相比于普通的三元组,增加了时间信息,因此在动态知识图谱中,实体之间的可能通过多个相同的关系连接,但是这些关系会关联到不同的时序信息。Know-Evolve 中,使用时间点过程(temporal point process)来描述时间点的影响。
在时间点过程中,某一时刻发生某事件的概率可以表示为:
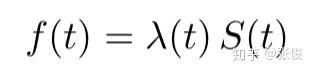
其中:
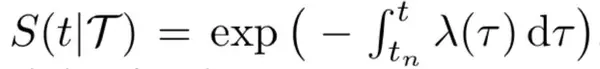

具体而言,Know-Evolve 中使用了 Rayleigh 过程来表示 λ(t),并使用一个神经网络来拟合 Rayleigh 过程的参数,对于发生在时刻 t 的四元组,有:
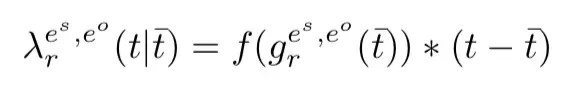

其中:
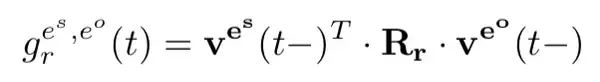

上式中,V 表示实体对应的向量表示,R 表示关系对应的矩阵,t-1 表示实体在上次被更新后的状态, \bar{t} 表示头实体或尾实体中最后被更改的时间。
此外,每次将新的四元组加入到动态知识库后,动态知识库中与该四元组相关的实体也会相应地进行更新,更新地过程用一个 RNN 来表示。
对于头实体,有:
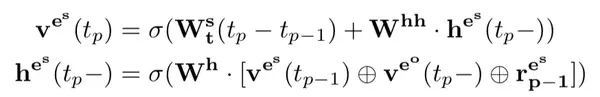

对于尾实体,有:
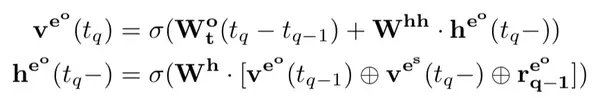

模型的训练通过最大化训练数据中四元组发生概率进行,对应的损失函数为对数损失函数。
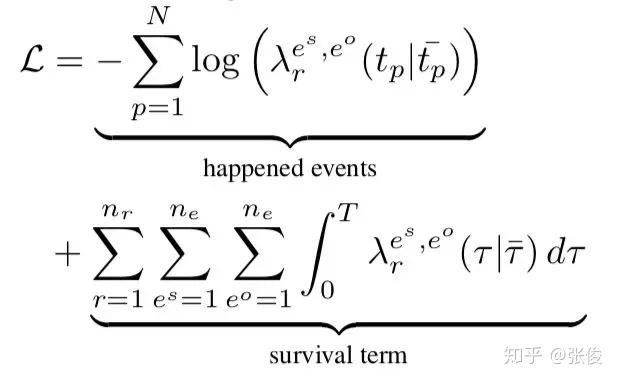

在损失函数中,后一项需要对头实体,关系,尾实体进行遍历,这个计算量是很大的,本文中使用了采样的方法来近似计算得到这部分的值。
实验使用了 GDELT 和 ICEWS 这两个时序知识库,相比于其他的方法,本文的结果均有限制的提升。
ICML 2017


■ 链接 | https://www.paperweekly.site/papers/1656
■ 源码 | https://github.com/quark0/ANALOGY
■ 解读 | 汪寒,浙江大学硕士,研究方向为知识图谱、自然语言处理
本文的主要创新点就是把类比推理应用到 KG embedding 中,通过对模型的 score function 添加某些约束来捕获 KG 中类比结构的信息,进而优化 KG 中实体和关系的 embedding 表示,并在 FB15K 和 WN18 数据集上达到 state-of -the-art 性能。
Analogical Structure
什么是类比结构?以 word embedding 中最著名的一句话为例,"man is to king aswoman is to queen",用 abcd 分别表示 man, king, woman, queen 四个实体,用 r 和 r' 表示 crown 和 male->female 关系,这就可以得到四个三元组。


可视化一下,就可以得到一个平行四边形结构,捕获这个结构的信息也就是本文的 motivation,且更复杂的类比结构的基本组成单元就是这个平行四边形结构。
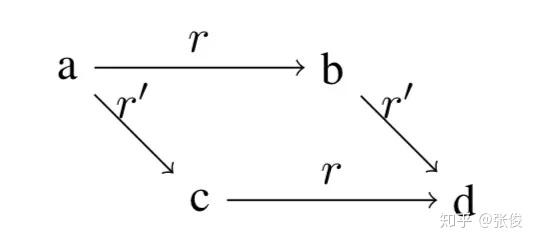

对于线性映射来说,一个理想的特性,就是所有有相同起点和终点的有向图,都形成了所谓的 compositional equivalence,在上图中就是 r\circ r'=r'\circ r ,且若关系集合 R 中任意两个关系都满足 compositional equivalence,则称 R 是一个 commuting family。
Method
本文将关系 r 视为线性映射,即给定三元组 (s,r,o),作者希望对于所有有效的三元组,都能满足 v_{s}^{T}W_{r}\approx v_{o}^{T} ,满足的程度就用一个 score function 表示,模型的目标就是学到恰当的 v 和 W,来让这个 score function 给有效的三元组高分,无效的三元组低分。为什么用线性映射而不用transE那样的加法映射呢?作者的看法是,用矩阵定义的线性映射表达能力比用向量定义的加法映射更强。
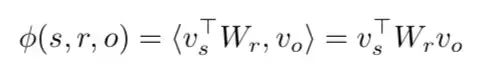

为了捕获 KG 中类比结构的信息,本文在objective function上加入了 Normal Matrix 和 compositional equivalence 的约束,而后者就是 W_{r\circ r'}=W_{r}W_{r'}=W_{r'}W_{r},即在线性映射上的具体实现,最后得到的 objective function 就是:
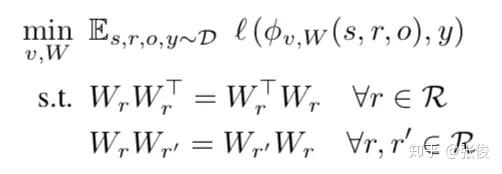

Why Normal Matrix
引理1,对于任意实正规矩阵 A,存在一个实正交矩阵 Q 和分块对角矩阵 B,满足 A=QBQT,其中 B 的每个对角块要么是个实数,要么是个 2 维实矩阵,x 和 y 都是实数。这个引理表明任意一个实正规矩阵都可以分块对角化。
引理 2,若一系列实正规矩阵组成了一个 commuting family,那么它们可以用同一个 Q 分块对角化。这个引理表明,若一个稠密关系矩阵集合{Wr}相互可交换,那么就可以同时被分块对角化成一个稀疏矩阵集合{Br}。
结合以上两个性质,可以对 score function 进行推导,过程如下:
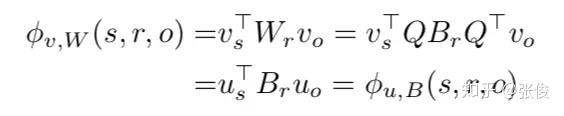

即对于任意目标函数 7 的解 (v*,W*) ,都有对应的 (u*,B*) 满足。


目标函数简化成了这个样子,其中 B 表示对角线上有 n 个实数的 m 阶对角方阵。
Unified View of Representative Methods
作者也证明了本文模型是 unified method,以 DistMult 为例,它的 score func 如:
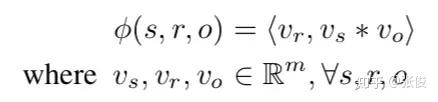

实际上这就是 n=m 的 ANALOGY 版本,其中 \phi(s,r,o)=v_{s}^{T}B_{r}v_{o} , B_{r}=diag(v_{r}) 。
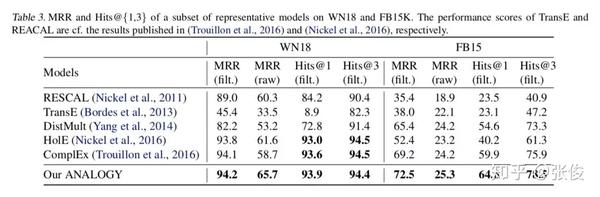
Experiments
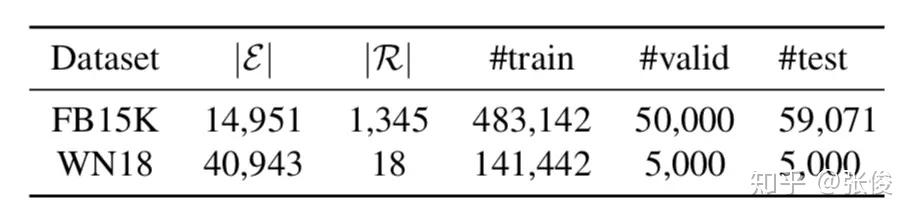
实验用的数据集是 FB15K 和 WN18,作者用了 19 个 baseline 做对比,metrics 用的也是常用的 MRR 和 Hits@k。由下表可以知道 FB15K 的关系数非常多,因此对其建模也更难,KG 中包含的类比结构也更多,而在这个数据集上,ANALOGY 的表现超过了所有 baseline 模型,这证明了捕获类比结构信息的作用。



而下图则表明在所有指标上,ANALOGY 的表现都超过了 DistMult,ComplEx 和 HolE,且这三个是 ANALOGY 的特例。

ACL 2017


■ 链接 | https://www.paperweekly.site/papers/2195
■ 解读 | 吴桐桐,东南大学博士生,研究方向为自然语言问答
导读
学术界近两年来十分关注如何将文本等非结构化数据和知识库等结构化数据映射到相同的语义空间中,然而在相同的语义空间中建模的过程会受到文本中实体指称(mention)歧义的影响,即文本中的同一个姓名如迈克尔·乔丹可能指的是著名的篮球运动员乔丹也可能是我们敬仰的教授乔丹,那么在语义空间中,因为他们的字面表达相同而将其建模成为统一的向量显然是不合理的。
因此,文中提出了一种新的 mention 向量表示的学习框架Multi-Prototype Entity Mention Embedding (MPME),它可以根据实体指称所对应的词义的不同而联合文本和知识库学习到不同的表示。
此外,文中提出了一种类似于语言模型的方法解决了实体指称的语义消歧问题。最后,实验部分利用实体链接任务作为 MPME 的应用场景,取得了当前最优的实验效果。
研究动机
当前有相当多的工作研究如何将文本和知识库进行关联建模,显然这样会为自然语言处理及知识库相关的研究任务带来比较大的性能提升。
当前的研究思路可以粗略地分为两类,其一是利用深度神经网络将实体和词语直接在统一的语义空间中进行建模,但这类方法比较受限于计算复杂度以及语料的规模。其二是分别对知识库中的实体以及文本中的实体指称进行建模,并且利用 wiki 百科中的外链获取 mention 和 entity 之间的关联,相当于在各自训练的过程中加入了一层约束用于确保他们在各自的语义空间中有相似的表达。
上述两类方法都会面对同一个实体指称可能对应到多个实体的歧义问题,即文本中提到的迈克尔乔丹可能是教授也可能是运动员或其他不甚知名的人,也会面临多个实体指称对应同一个实体的歧义问题,即文本中出现的姚明和小巨人可能指的同一个人。因此本文着手解决实体指称的语义歧义问题,类似于传统的实体链接任务。
创新点
本文提出了一种新型的实体指称表示学习方法 MPME,结合文本信息以及知识库信息学习实体指称的表示;此外,文中还提出了一种基于语言模型的决策方法来进行实体指称的语义消歧。
模型
本文使用的数据是从 New York Times 上抓取的 99872 篇文章。在定性分析中,apple,amazon,obama,trump 的词义变化轨迹如下所示:


如图所示,模型可以大致分成两个部分。
其一是表示学习部分,通过 Word Embedding 和 Knowledge Graph Embedding 对文本和知识库分别进行建模,其中每个实体指称都对应着一个实体集合,也就是它们潜在的语义。
在 Entity Representation Learning 中,训练的目标是有相似的关联实体的实体之间更相似。在 Text Representation Learning 中,实体指称将和其他词汇一起通过 Skip-Gram 模型进行训练,在Mention Representation Learning 中,实体指称被替换为相应的词义(sense),上下文的表示来自文本表示学习部分,实体的表示来自知识库表示学习部分,目标是得到更好的实体指称的表达 sj*,使得根据上下文信息,能够确定实体指称所对应的语义(对应哪个实体)。
其二是测试场景下的消歧部分,模型会综合考虑实体指称对应的上下文信息,以及实体指称对应各个语义的统计概率分布进行计算。
实验结果
文章的目标是训练得到一组高质量的实体指称向量,仍然没有跳出表示学习的框架,因此实验部分首先比较了采用 MPME 之后,训练得到的向量的相似实体指称都有哪些,以及从 mention embedding 和相应的 entity embedding 余弦距离的角度进行了分析,各项指标相对对比模型 SPME 提高了 1% 左右,这一部分就不做赘述了。
同时,文章利用 mention embedding 在实体链接任务上进行了验证,在 AIDA 数据集上,不管是有监督的实体链接任务还是无监督的实体链接任务,利用 MPME 均取得了相较于之前最好结果 3% 左右的提升。
启发
mention之间的信息
本文中把文本和知识库分别单独进行建模,mention 的建模过程中比较多的考虑 mention 和 entity 之间的关联,所谓的上下文更多的是以词窗口内词汇的形式出现的,而不是上下文中其他的 mention,因此有可能会忽略一些关键的信息。
传统的实体链接方法中比较多使用的一类是基于图的算法,其优势便在于能够更充分的发掘 mention 和 mention 之间,mention 和 entity 以及 entity 和 entity 直接的结构关联信息,利用这些信息进行消歧已经足够有效(体现在实体链接任务的准确率上),那么也可以尝试利用图结构更好地学习 mention 的表示。
潜在的问题在于,假设 mention 所对应的两个歧义实体属于同一个 category,那么它们会共享十分相似的上下文,通过本文所题出的方法将不能很好的解决这个问题。比如两只都叫做旺财的狗,它们的日常表现应该会比较相似,唯一不同的可能就只有它们的主人不同,这一点需要上下文中 mention 的参与,共同建模。
未登录词的处理
实际的应用场景中,未登录 mention 的数目理应远多于已经训练的 mention 的数目,这样才能体现出模型或方法的泛化能力,这也为我们提出更加 general 的 framework 提出的新的需求,或者说,训练的过程尽可能简单,所需的额外信息尽可能的少,对未登录词的发现更加友好的框架。
NIPS 2017


■ 链接 | https://www.paperweekly.site/papers/2193
■ 源码 | https://github.com/fanyangxyz/Neural-LP
■ 解读 | 张文,浙江大学博士生,研究方向为知识图谱的分布式表示与推理
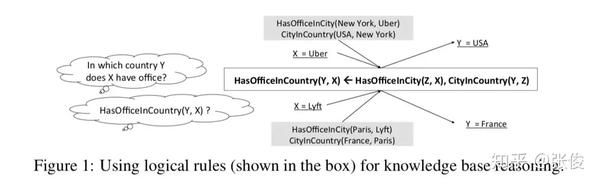
动机
本文提出了一个可微的基于知识库的逻辑规则学习模型。现在有很多人工智能和机器学习的工作在研究如何学习一阶逻辑规则,规则示例如下图:

形式化本文关心的逻辑规则如下:
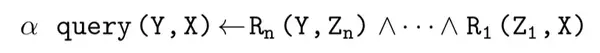

每一个规则由多个约束条件组合而成,并且被赋予一个置信度 α,其中 query(Y,X) 表示一个三元组,query 表示一个关系。
不同于基于 embedding 的知识库推理,规则应该是实体无关的,规则可以应用于任何新添加到知识库中的实体,但在知识库 embedding 方法里,新添加到知识库中的实体由于没有对应的表示,无法就这些实体进行相关的推理。
不同于以往的基于搜索和随机游走的规则学习方法,本文的目标是提出一个可微的一阶谓词逻辑规则学习模型,可用基于梯度的方法进行优化求解。
本文提出的 Neural LP 模型主要收到 TensorLog 的启发。TensorLog 可视为一个可微的推理机。知识库中的每个实体用一个 one-hot 向量表示,每个关系 r 定义为一个矩阵算子 M_r,M_r 为一个稀疏的毗连矩阵,维度为 n_e×n_e, 其中 n_e 表示实体的个数。每一条逻辑规则的右边部分被表示为以下形式:
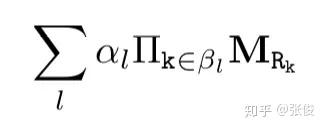
所以总结本文关心的优化问题如下:


V_{x} 和 V_{y} 分别为一个由规则推理得到的三元组。在上式的优化问题中,算法需要学习的部分分为两个:一个是规则的结构,即一个规则是由哪些条件组合而成的;另一个是规则的置信度。
由于每一条规则的置信度都是依赖于具体的规则形式,而规则结构的组成也是一个离散化的过程,因此上式整体是不可微的。因此作者对前面的式子做了以下更改:
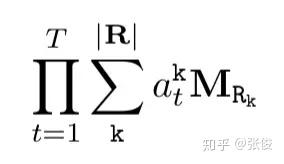
主要交换了连乘和累加的计算顺序,对预一个关系的相关的规则,为每个关系在每个步骤都学习了一个权重,即上式的 a_{l}^{k} 。其中 T 为超参,表示规则的长度。由于上式固定了每个规则的长度都为 T,这显然是不合适的。
为了能够学习到变长的规则,Neural LP 中设计了记忆向量 u_{t} ,表示每个步骤输出的答案——每个实体作为答案的概率分布,还设计了两个注意力向量:一个为记忆注意力向量 b_{t} ——表示在步骤 t 时对于之前每个步骤的注意力;一个为算子注意力向量 a_{t} ——表示在步骤 t 时对于每个关系算子的注意力。
每个步骤的输出由下面三个式子生成:
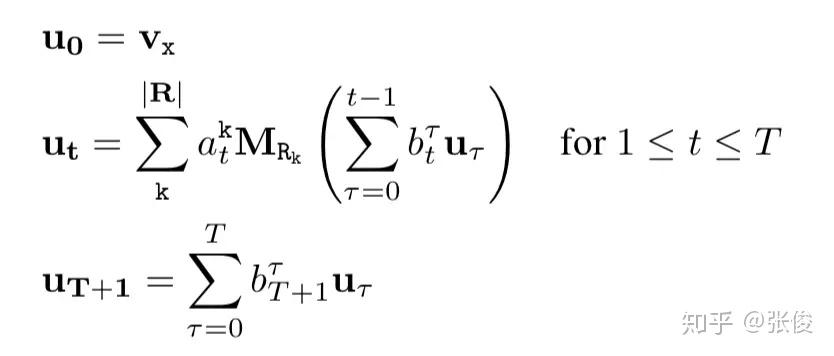

其中 a_{t} 和 b_{t} 基于一个 RNN 生成,具体如下:
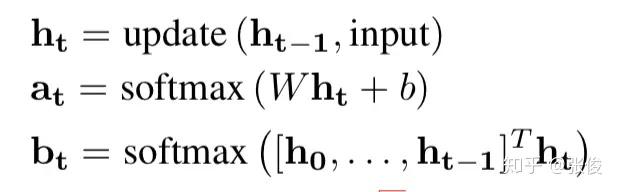

其中隐层变量 h_{t} 由一个 LSTM 生成。
本文还设计了一个根据训练结果解析规则的算法如下:


实验
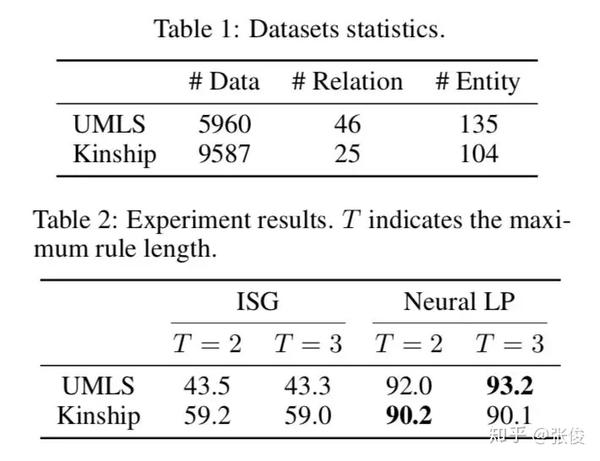
本文的实验相当丰富,主要包括:
1. 两个标准数据集上的统计关系学习相关的实验

2. 在 1616 的网格上的路径寻找的实验


3. 知识库补全实验
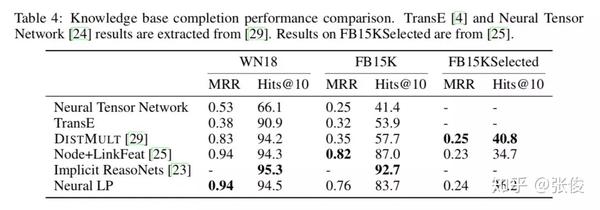

为了证明 Neural LP 的归纳推理的能力,本文还特别设计了一个实验,在训练数据集中去掉所有涉及测试集中包含的实体的三元组,然后训练并预测,得到结果如下:
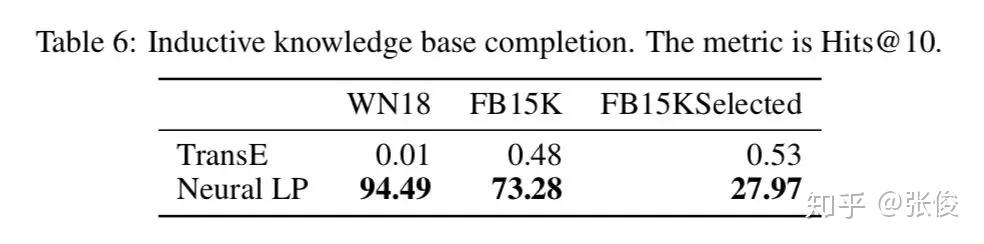

这个实验有效地证明了 Neural LP 的归纳推理的能力。
4. 知识库问答的实验


总结
本文提出了一个可微的规则学习模型,并强调了知识库中的规则应该是实体无关的,非常值得借鉴。有兴趣的读者可以阅读一下原文。
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
加入社区:http://paperweek.ly
微信公众号:PaperWeekly
新浪微博:@PaperWeekly
