第二篇
前面实现了一个最基础的爬取单网页的爬虫,这一篇则着手解决深度爬取的问题
简单来讲,就是爬了一个网页之后,继续爬这个网页中的链接
1. 需求背景
背景比较简单和明确,当爬了一个网页之后,目标是不要就此打住,扫描这个网页中的链接,继续爬,所以有几个点需要考虑:
- 哪些链接可以继续爬 ?
- 是否要一直爬下去,要不要给一个终止符?
- 新的链接中,提取内容的规则和当前网页的规则不一致可以怎么办?
2. 设计
针对上面的几点,结合之前的实现结构,在执行 doFetchPage 方法获取网页之后,还得做一些其他的操作
- 扫描网页中的链接,根据过滤规则匹配满足要求的链接
- 记录一个 depth,用于表示爬取的深度,即从最原始的网页出发,到当前页面中间转了几次(讲到这里就有个循环爬取的问题,后面说)
- 不同的页面提取内容规则不一样,因此可以考虑留一个接口出来,让适用方自己来实现解析网页内容
基本实现
开始依然是先把功能点实现,然后再考虑具体的优化细节
先加一个配置项,表示爬取页面深度; 其次就是保存的结果,得有个容器来暂存, 所以在 SimpleCrawlJob 会新增两个属性
/**
* 批量查询的结果
*/
private List<CrawlResult> crawlResults = new ArrayList<>();
/**
* 爬网页的深度, 默认为0, 即只爬取当前网页
*/
private int depth = 0;
因为有深度爬取的过程,所以需要修改一下爬取网页的代码,新增一个 doFetchNetxtPage 方法,进行迭代爬取网页,这时,结果匹配处理方法也不能如之前的直接赋值了,稍微改一下即可, 改成返回一个接过实例
/**
* 执行抓取网页
*/
public void doFetchPage() throws Exception {
doFetchNextPage(0, this.crawlMeta.getUrl());
this.crawlResult = this.crawlResults.get(0);
}
private void doFetchNextPage(int currentDepth, String url) throws Exception {
HttpResponse response = HttpUtils.request(new CrawlMeta(url, this.crawlMeta.getSelectorRules()), httpConf);
String res = EntityUtils.toString(response.getEntity());
CrawlResult result;
if (response.getStatusLine().getStatusCode() != 200) { // 请求成功
result = new CrawlResult();
result.setStatus(response.getStatusLine().getStatusCode(), response.getStatusLine().getReasonPhrase());
result.setUrl(crawlMeta.getUrl());
this.crawlResults.add(result);
return;
}
result = doParse(res);
// 超过最大深度, 不继续爬
if (currentDepth > depth) {
return;
}
Elements elements = result.getHtmlDoc().select("a[href]");
for(Element element: elements) {
doFetchNextPage(currentDepth + 1, element.attr("href"));
}
}
private CrawlResult doParse(String html) {
Document doc = Jsoup.parse(html);
Map<String, List<String>> map = new HashMap<>(crawlMeta.getSelectorRules().size());
for (String rule : crawlMeta.getSelectorRules()) {
List<String> list = new ArrayList<>();
for (Element element : doc.select(rule)) {
list.add(element.text());
}
map.put(rule, list);
}
CrawlResult result = new CrawlResult();
result.setHtmlDoc(doc);
result.setUrl(crawlMeta.getUrl());
result.setResult(map);
result.setStatus(CrawlResult.SUCCESS);
return result;
}
说明
主要的关键代码在 doFetchNextPage 中,这里有两个参数,第一个表示当前 url 属于爬取的第几层,爬完之后,判断是否超过最大深度,如果没有,则获取出网页中的所有链接,迭代调用一遍
下面主要是获取网页中的跳转链接,直接从 jsoup 的源码中的 example 中获取,获取网页中链接的方法
// 未超过最大深度, 继续爬网页中的所有链接
result = doParse(res);
Elements elements = result.getHtmlDoc().select("a[href]");
for(Element element: elements) {
doFetchNextPage(currentDepth + 1, element.attr("href"));
}
测试 case
测试代码和之前的差不多,唯一的区别就是指定了爬取的深度,返回结果就不截图了,实在是有点多
/**
* 深度爬
* @throws InterruptedException
*/
@Test
public void testDepthFetch() throws InterruptedException {
String url = "https://my.oschina.net/u/566591/blog/1031575";
CrawlMeta crawlMeta = new CrawlMeta();
crawlMeta.setUrl(url);
SimpleCrawlJob job = new SimpleCrawlJob(1);
job.setCrawlMeta(crawlMeta);
Thread thread = new Thread(job, "crawlerDepth-test");
thread.start();
thread.join();
List<CrawlResult> result = job.getCrawlResults();
System.out.println(result);
}
3. 改进
问题
上面虽然是实现了目标,但问题却有点多:
-
就比如上面的测试 case,发现有 122 个跳转链接,顺序爬速度有点慢

-
链接中存在重复、页面内锚点、js 等各种情况,并不是都满足需求
-
最后的结果塞到 List 中,深度较多时,链接较多时,list 可能被撑暴
- 添加链接的过滤
过滤规则,可以划分为两种,正向的匹配,和逆向的排除
首先是修改配置类 CrawlMeta, 新增两个配置
/**
* 正向的过滤规则
*/
@Setter
@Getter
private Set<Pattern> positiveRegex = new HashSet<>();
/**
* 逆向的过滤规则
*/
@Setter
@Getter
private Set<Pattern> negativeRegex = new HashSet<>();
public Set<Pattern> addPositiveRegex(String regex) {
this.positiveRegex.add(Pattern.compile(regex));
return this.positiveRegex;
}
public Set<Pattern> addNegativeRegex(String regex) {
this.negativeRegex.add(Pattern.compile(regex));
return this.negativeRegex;
}
然后在遍历子链接时,判断一下是否满足需求
// doFetchNextPage 方法
Elements elements = result.getHtmlDoc().select("a[href]");
String src;
for(Element element: elements) {
src = element.attr("href");
if (matchRegex(src)) {
doFetchNextPage(currentDepth + 1, element.attr("href"));
}
}
// 规则匹配方法
private boolean matchRegex(String url) {
Matcher matcher;
for(Pattern pattern: crawlMeta.getPositiveRegex()) {
matcher = pattern.matcher(url);
if (matcher.find()) {
return true;
}
}
for(Pattern pattern: crawlMeta.getNegativeRegex()) {
matcher = pattern.matcher(url);
if(matcher.find()) {
return false;
}
}
return crawlMeta.getPositiveRegex().size() == 0;
}
上面主要是通过正则来进行过滤,暂不考虑正则带来的开销问题,至少是解决了一个过滤的问题
但是,但是,如果网页中的链接是相对路径的话,会怎么样
直接使用 Jsoup 来测试一个网页,看获取的 link 地址为什么
// 获取网页中的所有链接
@Test
public void testGetLink() throws IOException {
String url = "http://chengyu.911cha.com/zishu_3_p1.html";
Connection httpConnection = HttpConnection.connect(url)
.header("accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8")
.header("connection", "Keep-Alive")
.header("user-agent", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36");
Document doc = httpConnection.get();
Elements links = doc.select("a[href]");
print("\nLinks: (%d)", links.size());
}
看下取出的链接
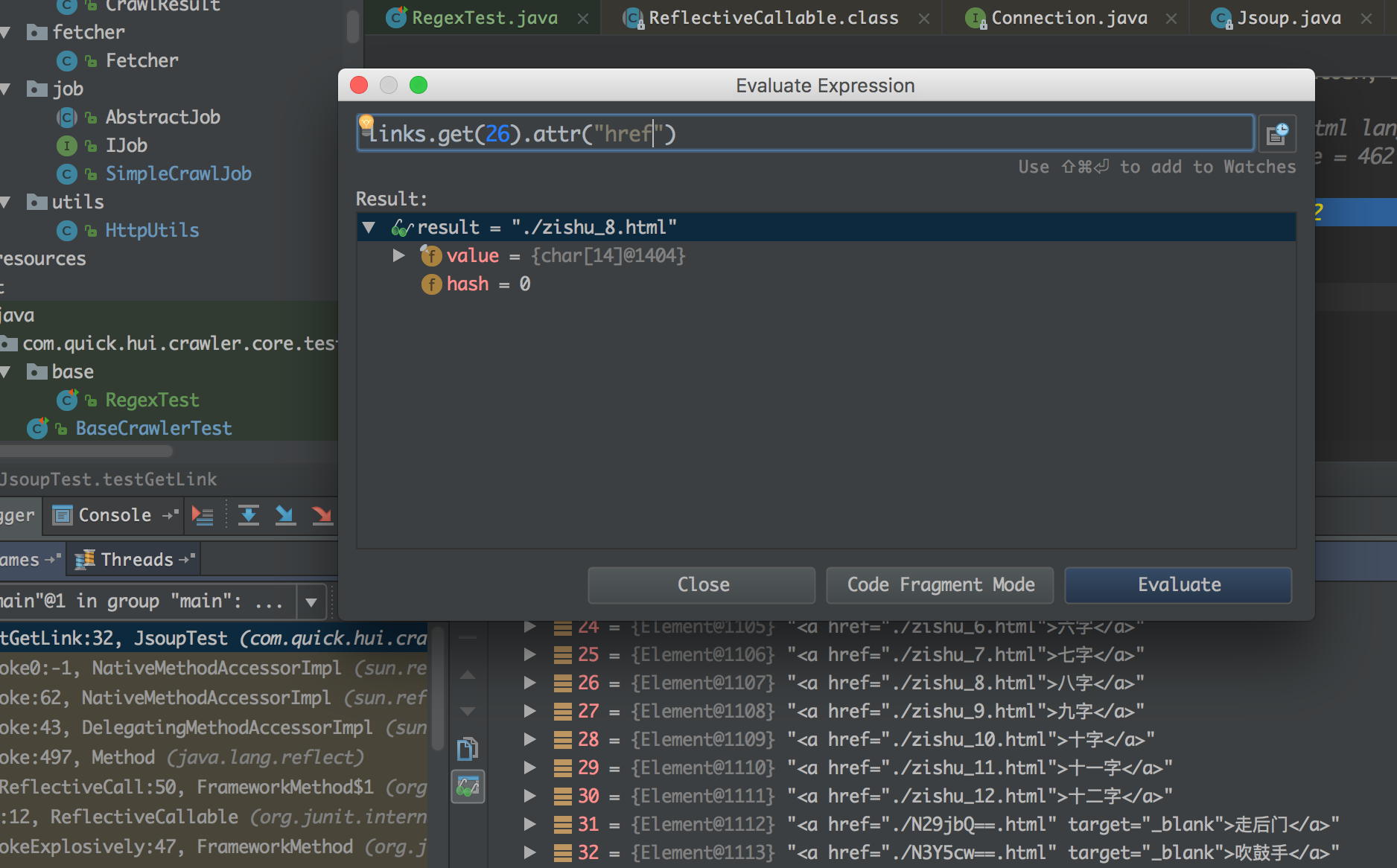
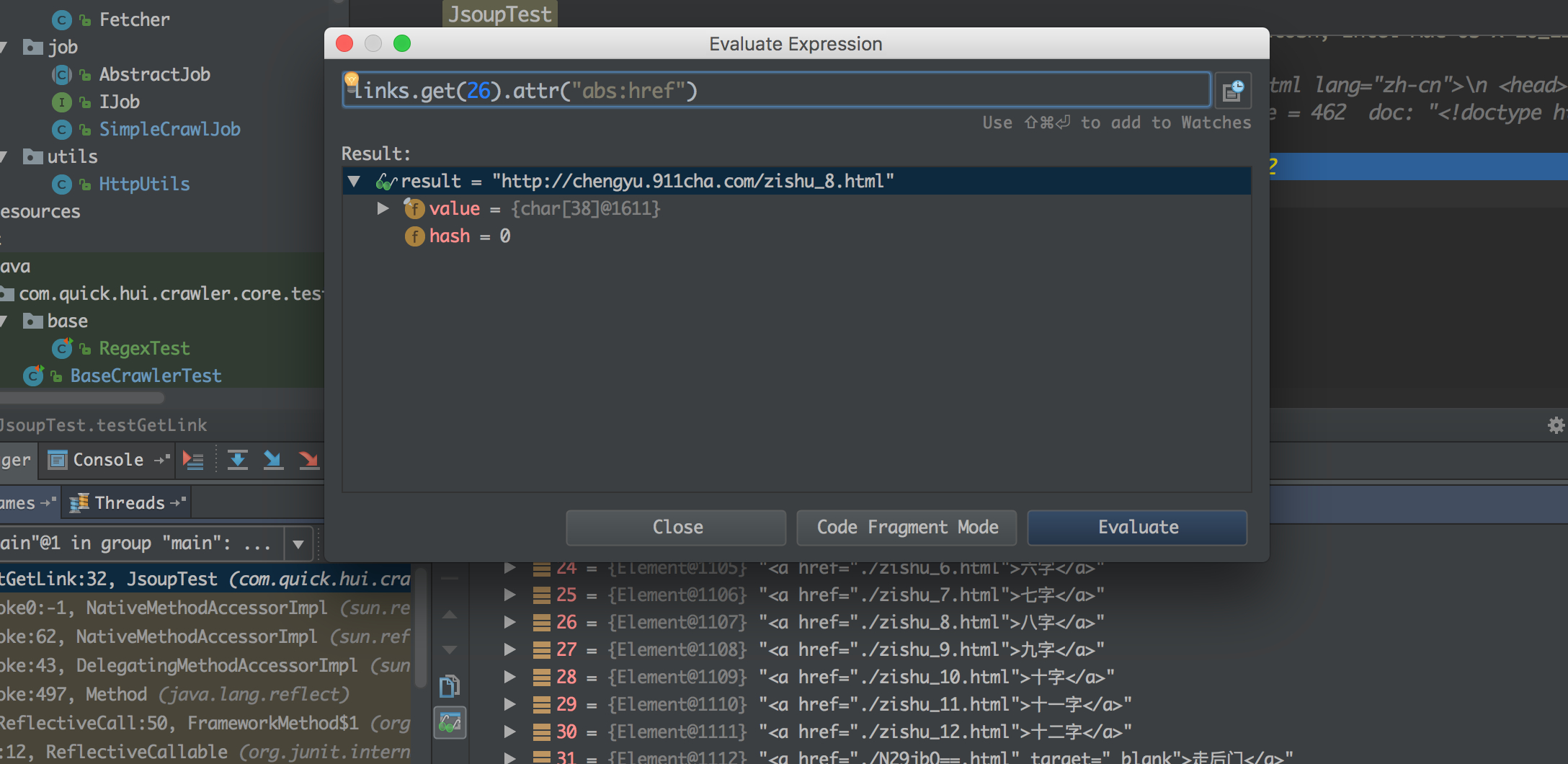
根据上面的测试,获取的链接如果是相对地址,则会有问题,需要有一个转化的过程,这个改动比较简单,jsoup 本身是支持的
改一行即可
// 解析为documnet对象时,指定 baseUrl
// 上面的代码结构会做一点修改,后面会说到
Document doc = Jsoup.parse(html, url);
// 获取链接时,前面添加abs
src = element.attr("abs:href");
- 保存结果
当爬取的数据量较多时,将结果都保存在内存中,并不是一个好的选择,假色每个网页中,满足规则的是有 10 个,那么 depth=n, 则从第一个网页出发,最终会得到
1 + 10 + ... + 10^n = (10^(n+1) - 1) / 9
显然在实际情况中是不可取的,因此可以改造一下,获取数据后给一个回调,让用户自己来选择如何处理结果,这时 SimpleCrawelJob 的结构基本上满足不了需求了
重新开始设计
1. AbstractJob 类中定义一个回调方法
/**
* 解析完网页后的回调方法
*
* @param crawlResult
*/
protected abstract void visit(CrawlResult crawlResult);
2. DefaultAbstractCrawlJob 实现爬取网页逻辑的抽象类
这个类实现爬取网页的主要逻辑,也就是将之前的 SimpleCrwalJob 的实现拷贝过来,区别是干掉了返回结果; 顺带修了一个小 bug
/**
* Created by yihui on 2017/6/29.
*/
@Getter
@Setter
@NoArgsConstructor
public abstract class DefaultAbstractCrawlJob extends AbstractJob {
/**
* 配置项信息
*/
private CrawlMeta crawlMeta;
/**
* http配置信息
*/
private CrawlHttpConf httpConf = new CrawlHttpConf();
/**
* 爬网页的深度, 默认为0, 即只爬取当前网页
*/
protected int depth = 0;
public DefaultAbstractCrawlJob(int depth) {
this.depth = depth;
}
/**
* 执行抓取网页
*/
public void doFetchPage() throws Exception {
doFetchNextPage(0, this.crawlMeta.getUrl());
}
private void doFetchNextPage(int currentDepth, String url) throws Exception {
CrawlMeta subMeta = new CrawlMeta(url, this.crawlMeta.getSelectorRules(), this.crawlMeta.getPositiveRegex(), this.crawlMeta.getNegativeRegex());
HttpResponse response = HttpUtils.request(subMeta, httpConf);
String res = EntityUtils.toString(response.getEntity());
CrawlResult result;
if (response.getStatusLine().getStatusCode() != 200) { // 请求成功
result = new CrawlResult();
result.setStatus(response.getStatusLine().getStatusCode(), response.getStatusLine().getReasonPhrase());
result.setUrl(crawlMeta.getUrl());
this.visit(result);
return;
}
// 网页解析
result = doParse(res, subMeta);
// 回调用户的网页内容解析方法
this.visit(result);
// 超过最大深度, 不继续爬
if (currentDepth > depth) {
return;
}
Elements elements = result.getHtmlDoc().select("a[href]");
String src;
for(Element element: elements) {
// 确保将相对地址转为绝对地址
src = element.attr("abs:href");
if (matchRegex(src)) {
doFetchNextPage(currentDepth + 1, src);
}
}
}
private CrawlResult doParse(String html, CrawlMeta meta) {
// 指定baseUrl, 否则利用 abs:href 获取链接会出错
Document doc = Jsoup.parse(html, meta.getUrl());
Map<String, List<String>> map = new HashMap<>(meta.getSelectorRules().size());
for (String rule : crawlMeta.getSelectorRules()) {
List<String> list = new ArrayList<>();
for (Element element : doc.select(rule)) {
list.add(element.text());
}
map.put(rule, list);
}
CrawlResult result = new CrawlResult();
result.setHtmlDoc(doc);
result.setUrl(meta.getUrl());
result.setResult(map);
result.setStatus(CrawlResult.SUCCESS);
return result;
}
private boolean matchRegex(String url) {
Matcher matcher;
for(Pattern pattern: crawlMeta.getPositiveRegex()) {
matcher = pattern.matcher(url);
if (matcher.find()) {
return true;
}
}
for(Pattern pattern: crawlMeta.getNegativeRegex()) {
matcher = pattern.matcher(url);
if(matcher.find()) {
return false;
}
}
return crawlMeta.getPositiveRegex().size() == 0;
}
}
3. SimpleCrawlJob
重写这个简单爬虫任务的实现,因为主要逻辑在 DefaultAbstractCrawlJob 中已经实现了,所以直接继承过来即可
主要关注的就是 visit 方法,这里就是爬取网页之后的回调,这个最简单的爬虫任务,就是将结果保存在内存中
/**
* 最简单的一个爬虫任务
* <p>
* Created by yihui on 2017/6/27.
*/
@Getter
@Setter
@NoArgsConstructor
public class SimpleCrawlJob extends DefaultAbstractCrawlJob {
/**
* 存储爬取的结果
*/
private CrawlResult crawlResult;
/**
* 批量查询的结果
*/
private List<CrawlResult> crawlResults = new ArrayList<>();
public SimpleCrawlJob(int depth) {
super(depth);
}
@Override
protected void visit(CrawlResult crawlResult) {
crawlResults.add(crawlResult);
}
public CrawlResult getCrawlResult() {
if(crawlResults.size() == 0) {
return null;
}
return crawlResults.get(0);
}
}
4,使用测试
和之前没有任何区别,先来个简单的
@Test
public void testDepthFetch() throws InterruptedException {
String url = "http://chengyu.911cha.com/zishu_3_p1.html";
CrawlMeta crawlMeta = new CrawlMeta();
crawlMeta.setUrl(url);
crawlMeta.addPositiveRegex("http://chengyu.911cha.com/zishu_3_p([0-9]+).html");
SimpleCrawlJob job = new SimpleCrawlJob(1);
job.setCrawlMeta(crawlMeta);
Thread thread = new Thread(job, "crawlerDepth-test");
thread.start();
thread.join();
List<CrawlResult> result = job.getCrawlResults();
System.out.println(result);
}
运行截图
直接使用 DefaultAbstractCrawl 抽象类的回调来进行测试
@Test
public void testSelfCwralFetch() throws InterruptedException {
String url = "http://chengyu.911cha.com/zishu_3_p1.html";
CrawlMeta crawlMeta = new CrawlMeta();
crawlMeta.setUrl(url);
crawlMeta.addPositiveRegex("http://chengyu.911cha.com/zishu_3_p([0-9]+).html");
DefaultAbstractCrawlJob job = new DefaultAbstractCrawlJob(1) {
@Override
protected void visit(CrawlResult crawlResult) {
System.out.println(crawlResult.getUrl());
}
};
job.setCrawlMeta(crawlMeta);
Thread thread = new Thread(job, "crawlerDepth-test");
thread.start();
thread.join();
System.out.println("over");
}
- 爬虫去重
从上面可以发现,重复爬取是比较浪费的事情,因此去重是非常有必要的;一般想法是将爬过的 url 都标记一下,每次爬之前判断是否已经爬过了
依然先是采用最 low 的方法,搞一个 Set 来记录所有爬取的 url,因为具体的爬虫任务设计的是多线程的,所以这个 Set 是要求多线程共享的
此外考虑到去重的手段比较多,我们目前虽然只是采用的内存中加一个缓存表,但不妨碍我们设计的时候,采用面向接口的方式
1. IStorage 接口
提供存记录,判断记录是否存在的方法
public interface IStorage {
/**
* 若爬取的URL不在storage中, 则写入; 否则忽略
*
* @param url 爬取的网址
* @return true 表示写入成功, 即之前没有这条记录; false 则表示之前已经有记录了
*/
boolean putIfNotExist(String url, CrawlResult result);
/**
* 判断是否存在
* @param url
* @return
*/
boolean contains(String url);
}
2. RamStorage 利用 Map 实现的内存存储
public class RamStorage implements IStorage {
private Map<String, CrawlResult> map = new ConcurrentHashMap<>();
@Override
public boolean putIfNotExist(String url, CrawlResult result) {
if(map.containsKey(url)) {
return false;
}
map.put(url, result);
return true;
}
@Override
public boolean contains(String url) {
return map.containsKey(url);
}
}
3. StorageWrapper 封装类
这个封装类要求多线程共享,所以我们采用单例模式,保证只有一个实例
一个最原始的实现方式如下(暂不考虑其中比较猥琐的 storage 实例化方式)
public class StorageWrapper {
private static StorageWrapper instance = new StorageWrapper();
private IStorage storage;
public static StorageWrapper getInstance() {
return instance;
}
private StorageWrapper() {
storage = new RamStorage();
}
/**
* 判断url是否被爬取过
*
* @param url
* @return
*/
public boolean ifUrlFetched(String url) {
return storage.contains(url);
}
/**
* 爬完之后, 新增一条爬取记录
* @param url
* @param crawlResult
*/
public void addFetchRecord(String url, CrawlResult crawlResult) {
storage.putIfNotExist(url, crawlResult);
}
}
这样一个简单的保存爬取历史记录的容器就有了,那么在爬取时,就需要事前判断一下
对应的 DefaultAbstractCrawlJob#doFetchNextPage 方法更新如下
// fixme 非线程安全
private void doFetchNextPage(int currentDepth, String url) throws Exception {
if (StorageWrapper.getInstance().ifUrlFetched(url)) {
return;
}
CrawlMeta subMeta = new CrawlMeta(url, this.crawlMeta.getSelectorRules(), this.crawlMeta.getPositiveRegex(), this.crawlMeta.getNegativeRegex());
HttpResponse response = HttpUtils.request(subMeta, httpConf);
String res = EntityUtils.toString(response.getEntity());
CrawlResult result;
if (response.getStatusLine().getStatusCode() != HttpStatus.SC_OK) { // 请求成功
result = new CrawlResult();
result.setStatus(response.getStatusLine().getStatusCode(), response.getStatusLine().getReasonPhrase());
result.setUrl(crawlMeta.getUrl());
this.visit(result);
return;
}
// 网页解析
result = doParse(res, subMeta);
StorageWrapper.getInstance().addFetchRecord(url, result);
// 回调用户的网页内容解析方法
this.visit(result);
// 超过最大深度, 不继续爬
if (currentDepth > depth) {
return;
}
Elements elements = result.getHtmlDoc().select("a[href]");
String src;
for(Element element: elements) {
// 确保将相对地址转为绝对地址
src = element.attr("abs:href");
if (matchRegex(src)) {
doFetchNextPage(currentDepth + 1, src);
}
}
}
如果仔细看上面的方法,就会发现在多线程环境下,依然可能存在重复爬取的情况
如有两个 CrawlJob 任务,若爬取的是同一个 url,第一个任务爬取完,还没有回写到 Storage 时,第二个任务开始爬,这时,事前判断没有记录,然后通过之后开始爬,这时就依然会出现重复爬的问题
要解决这个问题,一个简单的方法就是加锁,在判断一个 url 没有被爬时,到回写一条爬取结果这段期间,加一个保护锁
StorageWrapper 更新后如下
/**
* Created by yihui on 2017/6/29.
*/
public class StorageWrapper {
private static StorageWrapper instance = new StorageWrapper();
private IStorage storage;
private Map<String, Lock> lockMap = new ConcurrentHashMap<>();
public static StorageWrapper getInstance() {
return instance;
}
private StorageWrapper() {
storage = new RamStorage();
}
/**
* 判断url是否被爬取过; 是则返回true; 否这返回false, 并上锁
*
* @param url
* @return
*/
public boolean ifUrlFetched(String url) {
if(storage.contains(url)) {
return true;
}
synchronized (this) {
if (!lockMap.containsKey(url)) {
// 不存在时,加一个锁
lockMap.put(url, new ReentrantLock());
}
this.lock(url);
if (storage.contains(url)) {
return true;
}
// System.out.println(Thread.currentThread() + " lock url: " + url);
return false;
}
}
/**
* 爬完之后, 新增一条爬取记录
* @param url
* @param crawlResult
*/
public void addFetchRecord(String url, CrawlResult crawlResult) {
try {
if (crawlResult != null) {
storage.putIfNotExist(url, crawlResult);
this.unlock(url);
}
} catch (Exception e) {
System.out.println(Thread.currentThread().getName() + " result: " + url + " e: " + e);
}
}
private void lock(String url) {
lockMap.get(url).lock();
}
private void unlock(String url) {
lockMap.get(url).unlock();
}
}
使用处,稍稍变动如下
private void doFetchNextPage(int currentDepth, String url) throws Exception {
CrawlResult result = null;
try {
// 判断是否爬过;未爬取,则上锁并继续爬取网页
if (StorageWrapper.getInstance().ifUrlFetched(url)) {
return;
}
CrawlMeta subMeta = new CrawlMeta(url, this.crawlMeta.getSelectorRules(), this.crawlMeta.getPositiveRegex(), this.crawlMeta.getNegativeRegex());
HttpResponse response = HttpUtils.request(subMeta, httpConf);
String res = EntityUtils.toString(response.getEntity());
if (response.getStatusLine().getStatusCode() != HttpStatus.SC_OK) { // 请求成功
result = new CrawlResult();
result.setStatus(response.getStatusLine().getStatusCode(), response.getStatusLine().getReasonPhrase());
result.setUrl(crawlMeta.getUrl());
this.visit(result);
return;
}
// 网页解析
result = doParse(res, subMeta);
} finally {
// 添加一条记录, 并释放锁
StorageWrapper.getInstance().addFetchRecord(url, result);
}
// 回调用户的网页内容解析方法
this.visit(result);
// 超过最大深度, 不继续爬
if (currentDepth > depth) {
return;
}
Elements elements = result.getHtmlDoc().select("a[href]");
String src;
for(Element element: elements) {
// 确保将相对地址转为绝对地址
src = element.attr("abs:href");
if (matchRegex(src)) {
doFetchNextPage(currentDepth + 1, src);
}
}
}
4. 测试
@Test
public void testSelfCwralFetch() throws InterruptedException {
String url = "http://chengyu.t086.com/gushi/1.htm";
CrawlMeta crawlMeta = new CrawlMeta();
crawlMeta.setUrl(url);
crawlMeta.addPositiveRegex("http://chengyu.t086.com/gushi/[0-9]+\\.htm$");
DefaultAbstractCrawlJob job = new DefaultAbstractCrawlJob(1) {
@Override
protected void visit(CrawlResult crawlResult) {
System.out.println("job1 >>> " + crawlResult.getUrl());
}
};
job.setCrawlMeta(crawlMeta);
String url2 = "http://chengyu.t086.com/gushi/2.htm";
CrawlMeta crawlMeta2 = new CrawlMeta();
crawlMeta2.setUrl(url2);
crawlMeta2.addPositiveRegex("http://chengyu.t086.com/gushi/[0-9]+\\.htm$");
DefaultAbstractCrawlJob job2 = new DefaultAbstractCrawlJob(1) {
@Override
protected void visit(CrawlResult crawlResult) {
System.out.println("job2 >>> " + crawlResult.getUrl());
}
};
job2.setCrawlMeta(crawlMeta2);
Thread thread = new Thread(job, "crawlerDepth-test");
Thread thread2 = new Thread(job2, "crawlerDepth-test2");
thread.start();
thread2.start();
thread.join();
thread2.join();
}
输出如下
job2 >>> http://chengyu.t086.com/gushi/2.htm
job1 >>> http://chengyu.t086.com/gushi/1.htm
job1 >>> http://chengyu.t086.com/gushi/3.htm
job2 >>> http://chengyu.t086.com/gushi/4.htm
job1 >>> http://chengyu.t086.com/gushi/5.htm
job1 >>> http://chengyu.t086.com/gushi/6.htm
job1 >>> http://chengyu.t086.com/gushi/7.htm
小结
这一篇的博文有点多,到这里其实上面一些提出的问题还没有解决,留待下一篇博文来 fix 掉, 下面则主要说明下本篇的要点
- 深度爬取
这里使用了迭代的思路,爬到一个网页之后,判断是否需要停止,不停止,则把该网页中的链接捞出来,继续爬;关键点
- 利用 Jsoup 获取网页中所有链接(注意相对路径转绝对路径的用法)
- 循环迭代
- 过滤
过滤,主要利用正则来匹配链接;这里需要注意一下几点
- 正向过滤
- 负向过滤
- 去重
如何保证一个链接被爬了之后,不会被重复进行爬取?
- 记录爬取历史
- 注意多线程安全问题
- 加锁(一把锁会导致性能降低,这里采用了一个url对应一个锁,注意看实现细节,较多的坑)
遗留问题
- 失败重试
- 爬网页中链接不应该串行进行
- 频率控制(太快可能会被反扒干掉)
源码地址: https://github.com/liuyueyi/quick-crawler/releases/tag/v0.003
对应 tag :v0.003
欢迎来到这里!
我们正在构建一个小众社区,大家在这里相互信任,以平等 • 自由 • 奔放的价值观进行分享交流。最终,希望大家能够找到与自己志同道合的伙伴,共同成长。
注册 关于