实际上是反反爬的技术,我对 JS 代码了解不多,看得头晕,有人会么?教教我,或者有教程之类的也行.
针对的机制的 crawlerInfo 加密函数,我找来找去,越来越乱,特此求助!
实际上是反反爬的技术,我对 JS 代码了解不多,看得头晕,有人会么?教教我,或者有教程之类的也行.
针对的机制的 crawlerInfo 加密函数,我找来找去,越来越乱,特此求助!
我们很熟悉爬虫,爬虫存在互联网的各个角落,爬虫有好处也有坏处,今天我们不讲如何进行爬取,我们来说一说和爬虫共同诞生的反爬虫技术。爬虫技术造成的大量 IP 访问网站侵占带宽资源、以及用户隐私和知识产权等危害,很多互联网企业都会花大力气进行“反爬虫”。相比于爬虫技术,反爬虫其实更复杂。在 90 年代开始有搜索引擎网站利用爬虫技术抓取网站时,一些搜索引擎从业者和网站站长通过邮件讨论定下了一项“君子协议”—— robots.txt。即网站有权规定网站中哪些内容可以被爬虫抓取,哪些内容不可以被爬虫抓取。这样既可以保护隐私和敏感信息,又可以被搜索引擎收录、增加流量。在远古时期,互联网还是一片乐土,大多数从业者都会默守这一协定,毕竟那时候信息和数据都没什么油水可捞。但很快互联网上开始充斥着商品信息、机票价格、个人隐私等等,在利益的诱惑下,自然有些人会开始违法爬虫协议了。当君子协议不再有效时,我们就采取技术的手段来反爬虫,今天我们主要说一说有那些技术方法来应对爬虫进行反爬。
**01
**
通过请求头来控制访问
不管是浏览器还是爬虫程序,在访问目标源网站时都会带上一个头文件:User-Agent
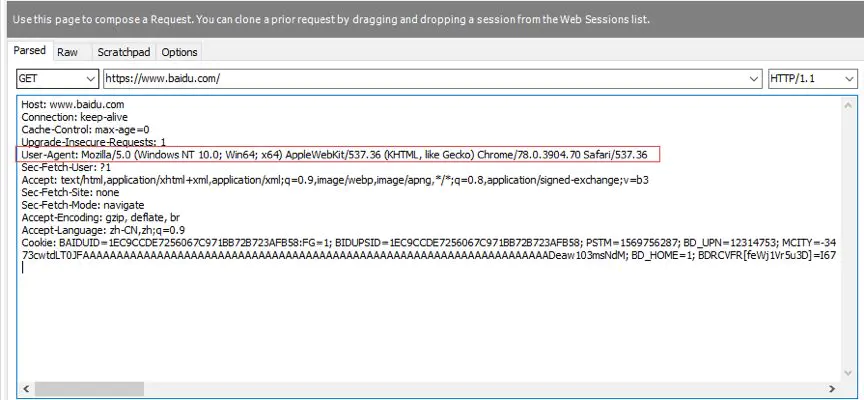
**反爬策略:**我们的网站可以设定 User-Agent 白名单,属于正常的范围才能访问
**缺点:**爬虫程序很容易伪造头部进行请求,只能拦截一部分新手爬虫。
**02
**
ip 限制
**反爬策略:**让一个固定的 ip 在短时间,不能对接口进行频繁访问。
**缺点:**爬虫程序可以通过 ip 代理池切换 ip 进行访问,但对爬虫者来讲需要一定成本,对于反爬虫来讲通过这种免费或付费的 ip 代理可以绕过检测。
*代理ip池实现的简单思路*@return*/public static Sting getProxy(){String [] proxy={“http://118.245.23.2:80”,“http://118.145.23.2:8118”,“http://117.245.23.2:88”,“http://116.245.23.2:80”};return proxy [new Random().nextInt(proxy.length)];}
**03
**
验证码验证
验证码是一种区分用户是计算机还是人的公共全自动程序。可以防止:恶意破解密码、刷票、论坛灌水,有效防止某个黑客对某一个特定注册用户用特定程序暴力破解方式进行不断的登陆尝试,实际上用验证码是现在很多网站通行的方式,我们利用比较简易的方式实现了这个功能。这个问题可以由计算机生成并评判,但是必须只有人类才能解答。由于 计算机无法解答 CAPTCHA 的问题,所以回答出问题的用户就可以被认为是人类。


**缺点:**影响正常的用户体验操作,验证码越复杂,网站体验感越差
**04
**
session 访问限制
**反爬措施:**后台统计登录用户的操作,比如短时间的点击事件,请求数据事件,与正常值比对,用于区分用户是否处理异常状态,如果是,则限制登录用户操作权限。
**缺点:**需要增加数据埋点功能,阈值设置不好,容易误杀。
**05
**
数据加密
**反爬措施:**前端可以通过对查询参数、user-agent、验证码、cookie 等前端数据进行加密生成一串加密指令,将加密指令作为参数,再进行服务器数据请求。该加密参数为空或者错误,服务器都不对请求进行响应;后端可以在服务器端同样有一段加密逻辑,生成一串编码,与请求的编码进行匹配,匹配通过则会返回数据。
**缺点:**加密算法写在 JS 里,爬虫程序经过一系列分析还是可以进行破解。
**06
**
但是目前面对这些反爬虫技术,如果我们为了获取数据又必须用爬虫技术,那么面对这种情况应该如何解决?
首先我先介绍Google Chrome的开发者工具的打开方式,我下面的介绍都是在Google Chrome里进行,所以这个开发者工具的使用比较重要。 首先打开Google Chrome,对于Mac而言Cmd+Opt+I Windows而言Ctrl+Shift+I
以此我们可以打开开发者工具
我们就以知乎为例进行解释
打开开发者工具之后,根据上图的步骤我们可以找到需要使用的网址。
然后在 Atom 里可以输入以下代码,从而形成一个 python 的文件。
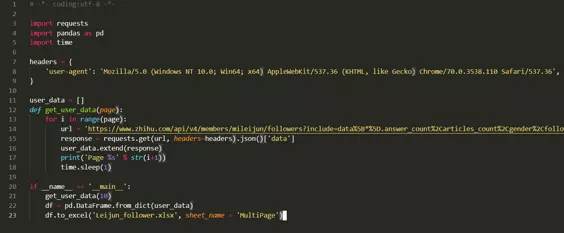
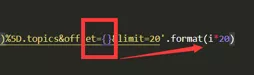
从而可以将数据爬取出来
我来 wolai:不仅仅是未来的云端笔记!
App(应用程序,Application 的缩写)一般指手机软件。
以太坊(Ethereum)并不是一个机构,而是一款能够在区块链上实现智能合约、开源的底层系统。以太坊是一个平台和一种编程语言 Solidity,使开发人员能够建立和发布下一代去中心化应用。 以太坊可以用来编程、分散、担保和交易任何事物:投票、域名、金融交易所、众筹、公司管理、合同和知识产权等等。
人工智能(Artificial Intelligence)是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门技术科学。
Dubbo 是一个分布式服务框架,致力于提供高性能和透明化的 RPC 远程服务调用方案,是 [阿里巴巴] SOA 服务化治理方案的核心框架,每天为 2,000+ 个服务提供 3,000,000,000+ 次访问量支持,并被广泛应用于阿里巴巴集团的各成员站点。
禅道是一款国产的开源项目管理软件,她的核心管理思想基于敏捷方法 scrum,内置了产品管理和项目管理,同时又根据国内研发现状补充了测试管理、计划管理、发布管理、文档管理、事务管理等功能,在一个软件中就可以将软件研发中的需求、任务、bug、用例、计划、发布等要素有序的跟踪管理起来,完整地覆盖了项目管理的核心流程。
据说 99% 的性能瓶颈都在数据库。
有点意思就行了
etcd 是一个分布式、高可用的 key-value 数据存储,专门用于在分布式系统中保存关键数据。
上帝为你关上了一扇门,然后就去睡觉了....努力不一定能成功,但不努力一定很轻松 (° ー °〃)
生活是指人类生存过程中的各项活动的总和,范畴较广,一般指为幸福的意义而存在。生活实际上是对人生的一种诠释。生活包括人类在社会中与自己息息相关的日常活动和心理影射。
iOS 是由苹果公司开发的移动操作系统,最早于 2007 年 1 月 9 日的 Macworld 大会上公布这个系统,最初是设计给 iPhone 使用的,后来陆续套用到 iPod touch、iPad 以及 Apple TV 等产品上。iOS 与苹果的 Mac OS X 操作系统一样,属于类 Unix 的商业操作系统。
Latke 是一款以 JSON 为主的 Java Web 框架。
MongoDB(来自于英文单词“Humongous”,中文含义为“庞大”)是一个基于分布式文件存储的数据库,由 C++ 语言编写。旨在为应用提供可扩展的高性能数据存储解决方案。MongoDB 是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。它支持的数据结构非常松散,是类似 JSON 的 BSON 格式,因此可以存储比较复杂的数据类型。
Swagger 是一款非常流行的 API 开发工具,它遵循 OpenAPI Specification(这是一种通用的、和编程语言无关的 API 描述规范)。Swagger 贯穿整个 API 生命周期,如 API 的设计、编写文档、测试和部署。
Python 是一种面向对象、直译式电脑编程语言,具有近二十年的发展历史,成熟且稳定。它包含了一组完善而且容易理解的标准库,能够轻松完成很多常见的任务。它的语法简捷和清晰,尽量使用无异义的英语单词,与其它大多数程序设计语言使用大括号不一样,它使用缩进来定义语句块。
七牛云是国内领先的企业级公有云服务商,致力于打造以数据为核心的场景化 PaaS 服务。围绕富媒体场景,七牛先后推出了对象存储,融合 CDN 加速,数据通用处理,内容反垃圾服务,以及直播云服务等。
ReactiveX 是一个专注于异步编程与控制可观察数据(或者事件)流的 API。它组合了观察者模式,迭代器模式和函数式编程的优秀思想。
Scala 是一门多范式的编程语言,集成面向对象编程和函数式编程的各种特性。
Git 是 Linux Torvalds 为了帮助管理 Linux 内核开发而开发的一个开放源码的版本控制软件。
Ruby 是一种开源的面向对象程序设计的服务器端脚本语言,在 20 世纪 90 年代中期由日本的松本行弘(まつもとゆきひろ/Yukihiro Matsumoto)设计并开发。在 Ruby 社区,松本也被称为马茨(Matz)。
DNSPod 建立于 2006 年 3 月份,是一款免费智能 DNS 产品。 DNSPod 可以为同时有电信、网通、教育网服务器的网站提供智能的解析,让电信用户访问电信的服务器,网通的用户访问网通的服务器,教育网的用户访问教育网的服务器,达到互联互通的效果。
Rust 是一门赋予每个人构建可靠且高效软件能力的语言。Rust 由 Mozilla 开发,最早发布于 2014 年 9 月。
Love2D 是一个开源的, 跨平台的 2D 游戏引擎。使用纯 Lua 脚本来进行游戏开发。目前支持的平台有 Windows, Mac OS X, Linux, Android 和 iOS。
欢迎来到这里!
我们正在构建一个小众社区,大家在这里相互信任,以平等 • 自由 • 奔放的价值观进行分享交流。最终,希望大家能够找到与自己志同道合的伙伴,共同成长。
注册 关于