插件地址:https://github.com/Achuan-2/siyuan-plugin-text-process
🤔 开发背景
从外部粘贴内容到思源笔记时,需要进行处理,希望这些处理能自动化,省去重复琐碎的操作,节省时间,有更多时间去思考创作。
比如很多 ai 默认生成的数学公式是 LaTeX 格式,粘贴到思源笔记不会渲染为公式
比如从 PPT、word 复制列表到思源,列表结构会丢失,需要自己重新写一个列表
比如从 pdf 复制的文字有多余的换行和空格,总是要手动删除
比如从维基百科复制到文字总是有很多链接和上标
……
✨ 插件功能
插件主要有两个功能
- 粘贴时自动处理
- 对块进行处理
粘贴时自动处理
在思源笔记的顶栏添加一个按钮,可以选择开启或关闭某个处理功能。
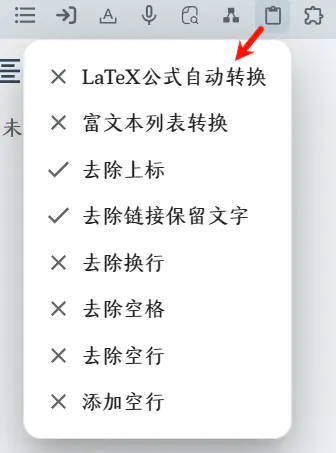
目前具有的功能:
-
LaTeX 行间数学公式(
\[...\])转为$$...$$格式,行内数学公式(\(...\))转为$...$格式 -
列表样式保留
- 用途:支持将 PPT、word 的列表样式粘贴思源笔记依然保留列表样式和层级结构,支持将•○▪▫◆◇►▻❖✦✴✿❀⚪☐ 符号的列表变为思源笔记列表格式)
-
去除上标
- 用途:去除维基百科等网站多余的上标
-
去除链接
- 用途:去除维基百科等网站多余的关键词链接
-
去除换行
- 用途:去除 pdf 复制的多余换行
-
去除空格
- 用途:去除 pdf 复制的多余空格
-
去除空行
- 用途:让粘贴内容全部都在一个块里
-
添加空行
- 用途:让粘贴内容一段一个块

注意:插件只影响外部纯文本粘贴和部分 html 粘贴,可能不影响 html 复制和思源笔记内部的富文本粘贴,如果发现不生效可以用右键菜单的纯文本粘贴来实现自动处理(虽然会丢格式,但暂时没法解决)。
对块进行处理
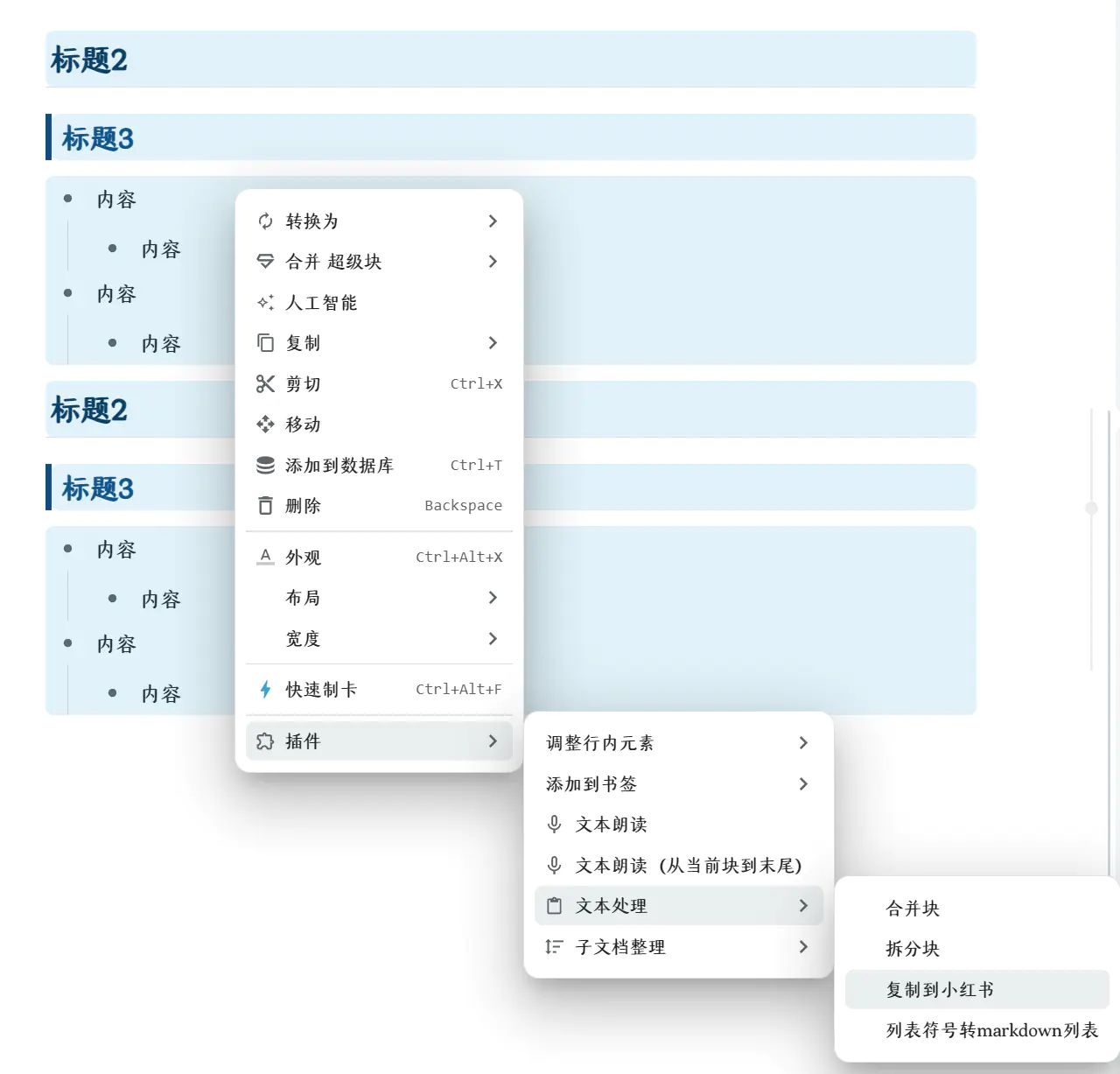
目前插件会给块菜单添加如下按钮
-
合并块【选中两个块及以上出现】
-
拆分块
-
列表符号转 markdown 列表
- 用途:将•○▪▫◆◇►▻❖✦✴✿❀⚪☐ 符号的列表变为思源笔记列表格式
-
仅复制一级列表(带符号)【仅选中一个列表块时出现】
- 用途:仅需要复制一级列表,分享给别人时使用
-
复制到小红书
- 用途:发小红书、发微信等纯文本场景,会将列表符号替换为指定符号
- 备注:有序列表使用数字 emoji1️⃣2️⃣3️⃣,无序列表可以在设置里指定符号,默认为 ■○

-
去除链接
-
去除上标

❤️ 用爱发电
如果喜欢我的插件,欢迎给 GitHub 仓库点 star 和捐赠,这会激励我继续完善此插件和开发新插件。

捐赠者列表见:https://www.yuque.com/achuan-2
开发笔记
加载插件数据和保存插件数据
加载插件数据
// 加载插件数据
await this.loadData(STORAGE_NAME);
console.log(this.data[STORAGE_NAME]);
保存插件数据
// 在前面设置配置默认值
this.data[STORAGE_NAME] = {
LaTeXConversion: false,
removeNewlines: false,
removeSpaces: false,
removeEmptyLines: false,
addEmptyLines: false,
pptList: false
}/
// 保存数据
this.saveData(STORAGE_NAME, this.data[STORAGE_NAME]);
LaTeX 行内公式和行间公式
if (this.data[STORAGE_NAME].LaTeXConversion) {
text = text.replace(/\\$$(.*?)\\$$/gs, '$$$$$1$$$$'); // LaTeX 行间数学公式块,允许中间有换行
text = text.replace(/\\$(.*?)\\$/g, '$$$1$$'); // LaTeX 行内数学公式
siyuan = siyuan.replace(/\\$$(.*?)\\$$/gs, '$$$$$1$$$$'); // LaTeX 行间数学公式块,允许中间有换行
siyuan = siyuan.replace(/\\$(.*?)\\$/g, '$$$1$$'); // LaTeX 行内数学公式
}
合并块
只有当前选中的块 detail.blockElements.length>1 时才出现,获取第一个 detail.blockElements 的 data-node-id,用 getBlockKramdown API 获取所有 detail.blockElements 的文本内容,去除每个块的 id 后,内容添加换行拼接在一起,用 updateBlock API 更新第一个块内容,之后需要删除其余的所有块
const firstBlockId = detail.blockElements[0].dataset.nodeId;
let mergedContent = '';
// Gather content from all blocks using SQL
for (const block of detail.blockElements) {
const blockId = block.dataset.nodeId;
const content = (await getBlockKramdown(blockId)).kramdown;
// Split content into lines
function cleanText(text) {
let lines = text.split('\n');
lines.pop(); // Remove last line
return lines.join('\n');
}
let contentClean = cleanText(content);
if (contentClean && contentClean.length > 0) {
console.log(contentClean)
mergedContent += contentClean + '\n';
}
}
// Update first block with merged content
await updateBlock('markdown', mergedContent.trim(), firstBlockId);
// Delete other blocks
for (let i = 1; i < detail.blockElements.length; i++) {
const blockId = detail.blockElements[i].dataset.nodeId;
await deleteBlock(blockId);
}
拆分块
获取每一个块 detail.blockElement 的 data-node-id 属性,根据 id 用 getBlockKramdown API 获取文本内容,过滤掉每个块的 id 之后,根据换行拆成一个个块
for (const block of detail.blockElements) {
const blockId = block.dataset.nodeId;
const content = (await getBlockKramdown(blockId)).kramdown;
console.log(content)
if (content && content.length > 0) {
// Split content into lines
function cleanText(text) {
return text
.split('\n')
.map(line => line.replace(/^[\s]*\{:[^}]*id="[^"]*"[^}]*\}/g, '').trim())
.filter(line => line) // 移除空行
.join('\n');
}
let contentClean = cleanText(content);
const lines = contentClean.split('\n');
console.log(lines);
if (lines.length > 1) {
// Update original block with first line
await updateBlock('markdown', lines[0], blockId);
// Insert remaining lines as new blocks
let previousId = blockId;
for (let i = 1; i < lines.length; i++) {
if (lines[i].trim()) { // Skip empty lines
await refreshSql();
const newBlock = await insertBlock('markdown', lines[i], null, previousId,null)
if (newBlock) {
previousId = newBlock[0].doOperations[0].id;
}
}
}
}
}
}
纯文本列表转 markdown 列表
for (const block of detail.blockElements) {
const blockId = block.dataset.nodeId;
const content = (await getBlockKramdown(blockId)).kramdown;
console.log(content)
if (content && content.length > 0) {
// Replace bullet points with markdown list syntax
const updatedContent = content.replace(/(^|\n)[•○▪▫◆◇►▻❖✦✴✿❀⚪☐][\s]*/g, '$1- ');
await updateBlock('markdown', updatedContent, blockId);
}
}
只复制列表第一层级
在 handleBlockMenu 的子菜单里在添加一个功能,如果选中的块只有一个,且是列表块(data.type="NodeList")只复制列表第一层级,先用 sql 获取 content,才通过正则,只提取第一层级的列表结构
word、ppt 列表粘贴保留样式
全部代码
private convertOfficeListToHtml(htmlString, type = 'auto') {
// 自动检测文档类型
const isWord = htmlString.includes('mso-list:l0 level');
const isPpt = htmlString.includes('mso-special-format');
// 如果没有检测到任何列表结构,直接返回原始HTML
if (!isWord && !isPpt) {
return htmlString;
}
// 自动判断类型
if (type === 'auto') {
if (isWord) type = 'word';
else if (isPpt) type = 'ppt';
}
// 根据类型调用对应的处理函数
switch (type.toLowerCase()) {
case 'word':
return isWord ? this.convertWordListToHtml(htmlString) : htmlString;
case 'ppt':
return isPpt ? this.convertPPTListToHtml(htmlString) : htmlString;
default:
return htmlString;
}
}
private convertWordListToHtml(htmlString) {
const parser = new DOMParser();
const doc = parser.parseFromString(htmlString, 'text/html');
const elements = Array.from(doc.body.children);
const result = [];
let listElements = [];
// 判断列表类型
function determineListType(element) {
const listMarker = element.querySelector('span[style*="mso-list:Ignore"]');
if (!listMarker) return 'ul'; // 默认无序列表
// 获取列表标记的实际文本内容
const markerText = listMarker.textContent.trim();
// 检查是否为有序列表的常见标记
// const isOrderedList = /^[0-9]+[.)]|^[a-zA-Z][.)]/.test(markerText);
const isOrderedList = markerText.length > 1;
return isOrderedList ? 'ol' : 'ul';
}
// 处理连续的列表组
function processListGroup(elements) {
if (elements.length === 0) return '';
const fragment = document.createDocumentFragment();
let currentList = null;
let previousLevel = 0;
let listStack = []; // 用于跟踪列表类型
elements.forEach(p => {
const style = p.getAttribute('style') || '';
const levelMatch = style.match(/level(\d+)/);
const currentLevel = parseInt(levelMatch[1]);
const listType = determineListType(p);
if (!currentList) {
// 创建第一个列表
currentList = document.createElement(listType);
fragment.appendChild(currentList);
listStack.push({ element: currentList, type: listType });
} else if (currentLevel > previousLevel) {
// 创建新的嵌套列表
const newList = document.createElement(listType);
currentList.lastElementChild.appendChild(newList);
currentList = newList;
listStack.push({ element: currentList, type: listType });
} else if (currentLevel < previousLevel) {
// 返回上层列表
for (let i = 0; i < previousLevel - currentLevel; i++) {
listStack.pop();
currentList = listStack[listStack.length - 1].element;
}
} else if (currentLevel === previousLevel && listType !== listStack[listStack.length - 1].type) {
// 同级但列表类型不同,创建新列表
const newList = document.createElement(listType);
if (listStack.length > 1) {
// 如果在嵌套中,添加到父列表项
currentList.parentElement.parentElement.appendChild(newList);
} else {
// 顶层列表,直接添加到片段
fragment.appendChild(newList);
}
currentList = newList;
listStack[listStack.length - 1] = { element: currentList, type: listType };
}
// 创建列表项
const li = document.createElement('li');
const pClone = p.cloneNode(true);
// 删除Word特有的列表标记
pClone.querySelectorAll('span[style*="mso-list:Ignore"]').forEach(span => {
span.remove();
});
li.innerHTML = pClone.innerHTML;
currentList.appendChild(li);
previousLevel = currentLevel;
});
const wrapper = document.createElement('div');
wrapper.appendChild(fragment);
return wrapper.innerHTML;
}
// 遍历所有元素
elements.forEach((element) => {
const style = element.getAttribute('style') || '';
const isListItem = style.includes('level') && style.includes('mso-list:');
if (isListItem) {
listElements.push(element);
} else {
if (listElements.length > 0) {
result.push(processListGroup(listElements));
listElements = [];
}
result.push(element.outerHTML);
}
});
// 处理最后一组列表元素
if (listElements.length > 0) {
result.push(processListGroup(listElements));
}
return result.join('\n');
}
private convertPPTListToHtml(htmlString) {
// 创建一个DOM解析器
const parser = new DOMParser();
const doc = parser.parseFromString(htmlString, 'text/html');
// 找到所有元素
const elements = Array.from(doc.body.children);
const result = [];
let listElements = [];
// 判断列表类型
function determineListType(element) {
const bulletSpan = element.querySelector('span[style*="mso-special-format"]');
if (!bulletSpan) return 'ul'; // 默认无序列表
const style = bulletSpan.getAttribute('style') || '';
// PPT中有序列表通常包含"numbullet"
const isOrderedList = style.includes('numbullet');
console.log(isOrderedList);
return isOrderedList ? 'ol' : 'ul';
}
// 处理连续的列表组
function processListGroup(elements) {
if (elements.length === 0) return '';
const fragment = document.createDocumentFragment();
let currentList = null;
let previousMargin = 0;
let listStack = []; // 用于跟踪列表类型
elements.forEach(div => {
const style = div.getAttribute('style') || '';
const marginMatch = style.match(/margin-left:([.\d]+)in/);
const currentMargin = parseFloat(marginMatch[1]);
const listType = determineListType(div);
if (!currentList) {
// 创建第一个列表
currentList = document.createElement(listType);
fragment.appendChild(currentList);
listStack.push({ element: currentList, type: listType, margin: currentMargin });
} else if (currentMargin > previousMargin) {
// 创建新的嵌套列表
const newList = document.createElement(listType);
currentList.lastElementChild.appendChild(newList);
currentList = newList;
listStack.push({ element: currentList, type: listType, margin: currentMargin });
} else if (currentMargin < previousMargin) {
// 返回上层列表
while (listStack.length > 0 && listStack[listStack.length - 1].margin > currentMargin) {
listStack.pop();
}
currentList = listStack[listStack.length - 1].element;
} else if (currentMargin === previousMargin && listType !== listStack[listStack.length - 1].type) {
// 同级但列表类型不同,创建新列表
const newList = document.createElement(listType);
if (listStack.length > 1) {
// 如果在嵌套中,添加到父列表项
currentList.parentElement.parentElement.appendChild(newList);
} else {
// 顶层列表,直接添加到片段
fragment.appendChild(newList);
}
currentList = newList;
listStack[listStack.length - 1] = { element: currentList, type: listType, margin: currentMargin };
}
// 创建列表项
const li = document.createElement('li');
const divClone = div.cloneNode(true);
// 删除PPT特有的列表标记
divClone.querySelectorAll('span[style*="mso-special-format"]').forEach(span => {
span.remove();
});
li.innerHTML = divClone.innerHTML;
currentList.appendChild(li);
previousMargin = currentMargin;
});
const wrapper = document.createElement('div');
wrapper.appendChild(fragment);
return wrapper.innerHTML;
}
// 遍历所有元素
elements.forEach((element) => {
const style = element.getAttribute('style') || '';
const hasBullet = element.querySelector('span[style*="mso-special-format"]');
if (hasBullet && style.includes('margin-left')) {
// 收集列表元素
listElements.push(element);
} else {
// 如果有待处理的列表元素,先处理它们
if (listElements.length > 0) {
result.push(processListGroup(listElements));
listElements = [];
}
// 保持非列表元素不变
result.push(element.outerHTML);
}
});
// 处理最后一组列表元素
if (listElements.length > 0) {
result.push(processListGroup(listElements));
}
return result.join('\n');
}
word、ppt 列表转换
由于 word 的 html 没有结构,复制到思源笔记里会丢失无序列表层级,我希望把 style 中含有 level 的 p 节点替换为 html 列表(ul>li 结构),并根据 level 后面的数字判断列表层级,完美还原 word 里的列表层级,并不影响列表前后的内容,这样我就可以把 word 的内容无损粘贴到思源笔记里了
word 的列表层级怎么区分
根据属性 mso-list: 中 level 后面的数字
- 第一层级就是 level1
- 第二层级就是 level2
PPT 的列表层级怎么区分
根据列表的 margin-left 来区别
word 有序列表和无序列表的区别
- 有序列表:里数字,比如 1.、1)、a.,都为两位以上字符
- 无序列表:里是字符,都只有两个字符
PPT 有序列表和无序列表结构的区别
- 无序列表:
'span[style*="mso-special-format"]中mso-special-format的值为 bullet - 有序列表:
'span[style*="mso-special-format"]中mso-special-format的值包含 numbullet
欢迎来到这里!
我们正在构建一个小众社区,大家在这里相互信任,以平等 • 自由 • 奔放的价值观进行分享交流。最终,希望大家能够找到与自己志同道合的伙伴,共同成长。
注册 关于