如果我们项目中用到 redis,那么一定会存在缓存与数据库双写的问题,今天就讲讲双写可能存在的问题和解决思路。
一般的做法是
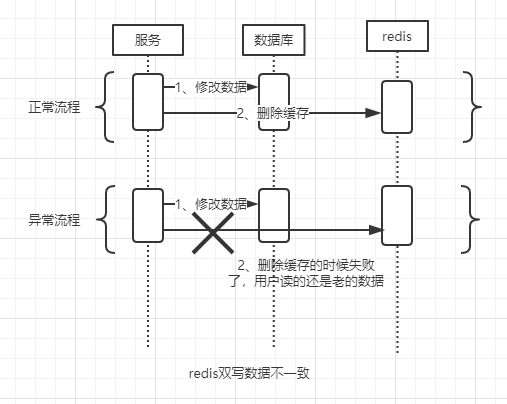
这样就出现缓存与数据库双写不一致了。那么如何解决呢?
其实很简单,只要把先后顺序换一下就好了,先删除缓存,再去修改数据库。
这里就引出了一个概念:cache aside pattern
(1)读的时候,先读缓存,缓存没有的话,那么就读数据库,然后取出数据后放入缓存,同时返回响应;
(2)更新的时候,先删除缓存,然后再更新数据库;
这个方法在并发不大的情况下是不会有问题的,但是如果你的系统读并发很高,那么会出现这样的情况:
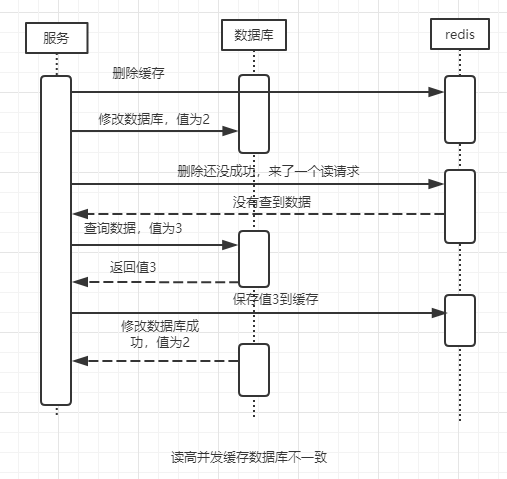
这时候,数据库里值为 2,缓存里面的值为 3,就出现数据不一致问题了。
那么这个问题怎么来解决呢?
可以通过数据库与缓存更新与读取操作进行异步串行化来解决这个问题

更新数据的时候,根据数据的唯一标识,将操作路由之后,发送到一个 jvm 内部的队列中,读取数据的时候,如果发现数据不在缓存中,那么将重新读取数据 + 更新缓存的操作,根据唯一标识路由之后,也发送同一个 jvm 内部的队列中,一个队列对应一个工作线程,每个工作线程串行拿到对应的操作,然后一条一条的执行,这样的话,一个数据变更的操作,先执行,删除缓存,然后再去更新数据库,但是还没完成更新,此时如果一个读请求过来,读到了空的缓存,那么可以先将缓存更新的请求发送到队列中,此时会在队列中积压,然后同步等待缓存更新完成,这里有一个优化点,一个队列中,其实多个更新缓存请求串在一起是没意义的,因此可以做过滤,如果发现队列中已经有一个更新缓存的请求了,那么就不用再放个更新请求操作进去了,直接等待前面的更新操作请求完成即可,待那个队列对应的工作线程完成了上一个操作的数据库的修改之后,才会去执行下一个操作,也就是缓存更新的操作,此时会从数据库中读取最新的值,然后写入缓存中,如果请求还在等待时间范围内,不断轮询发现可以取到值了,那么就直接返回; 如果请求等待的时间超过一定时长,那么这一次直接从数据库中读取当前的旧值
该解决方案要注意的问题:
1、读请求长时阻塞
如果写操作很频繁,那么队列中会积压很多写操作,导致读请求超时,走数据库,这里一定要多模拟线上环境,看看你并发最高的时候,请求是多少,来多次模拟,如果发现读请求超时过多,那么你需要加机器,让更多的队列来处理写请求。
2、读请求并发量过高
这里也是,需要多次模拟不同的情况,看并发过高的时候,服务器是否可以抗住,不行就加机器。
3、多服务实例部署的请求路由
可能这个服务部署了多个实例,那么必须保证说,执行数据更新操作,以及执行缓存更新操作的请求,都通过 nginx 服务器路由到相同的服务实例上
4、热点数据的路由问题,导致请求的倾斜
万一某个数据的读写请求特别高,全部打到相同的机器的相同的队列里面去了,可能造成某台机器的压力过大;就是说,因为只有在数据更新的时候才会清空缓存,然后才会导致读写并发,所以更新频率不是太高的话,这个问题的影响并不是特别大。但是的确可能某些机器的负载会高一些,因为毕竟有些数据的访问就是高一些。
注:每个人的问题可能都不一样,以上方案不一定完全适合你,不过设计思想是可以参考的。
redis 缓存全量更新问题
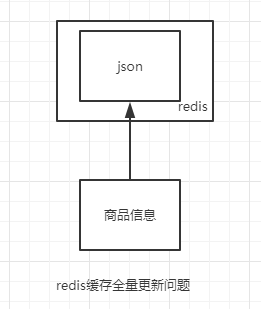
一般我们会把数据都以 json 格式存在 redis 里面,比如电商商品有分类、店铺信息、商品属性等等。如果分类变了,那需要把大 json 取下来,更新完,在保存到 redis 里面。这样的存储有几个不好的地方:
1、因为存储的数据比较大,所以网络开销比较大;
2、每次对 redis 做存取大数据,对 redis 的压力比较大;
3、数据本身的大小会影响 redis 的吞吐量和性能;
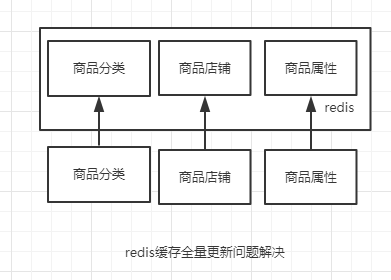
redis 缓存全量更新问题如何解决?
方法就是 redis 按维度化存储,把商品按照维度来拆分,比如商品分类,店铺信息、商品属性等,存储到 redis 的时候,也是按照维度来存储,这样原来你的 key 大小 200k,拆分完之后每个 key 的大小为 20k。大大提升了 redis 的性能和吞吐量。大大减少了网络资源的消耗,以及 redis 的压力。

欢迎来到这里!
我们正在构建一个小众社区,大家在这里相互信任,以平等 • 自由 • 奔放的价值观进行分享交流。最终,希望大家能够找到与自己志同道合的伙伴,共同成长。
注册 关于